Can AI Solve Data Silos Challenge? New Challenges To The Multi-AI Agents Era.
In this post, we are going to discuss what businesses encounter data silo challenges before the LLM era and the new hope LLM brings to the data ecosystem, and finally, we will explore some of the new challenges that emerge when we are using more vertical LLM agents to solve different purpose of scenarios.

Howard Chi
Updated: Dec 18, 2025
Published: Aug 20, 2024

Businesses have been struggling with data silo issues over the past decades. As we transition into the new LLM era, everyone is eager to utilize LLMs to solve data retrieval problems across data silos. However, we must consider whether this will improve the situation or worsen it.![blog-post_Can AI Solve Data Silos Challenge New Challenges To The Multi-AI Agents Era..png]
In this post, we are going to discuss what businesses encounter data silo challenges before the LLM era and the new hope LLM brings to the data ecosystem, and finally, we will explore some of the new challenges that emerge when we are using more vertical LLM agents to solve different purpose of scenarios.
The Data Silos
Businesses often face challenges with multiple systems and databases storing different data types. These data silos were a result of legacy systems and the lack of integration between them, leading to a fragmented view of data for users. This made data retrieval and comprehensive analysis difficult.
Today, companies still rely on manual efforts or third-party tools to integrate and centralize their data from various silos. This process is time-consuming and costly, often resulting in incomplete or inaccurate data. Consequently, decision-making is based on limited or outdated information, potentially leading to losses or missed opportunities for companies.

In an enterprise, the data infrastructure is several orders of magnitude complex, and business users usually need at least several weeks from request data to have the right to get access.
The lengthy data access workflow is due to diverse data sources and organizational complexity. Enterprises with multiple data sources need different technical experts to perform system integration and development. The costs of maintenance increase over time as the architecture becomes more complex.
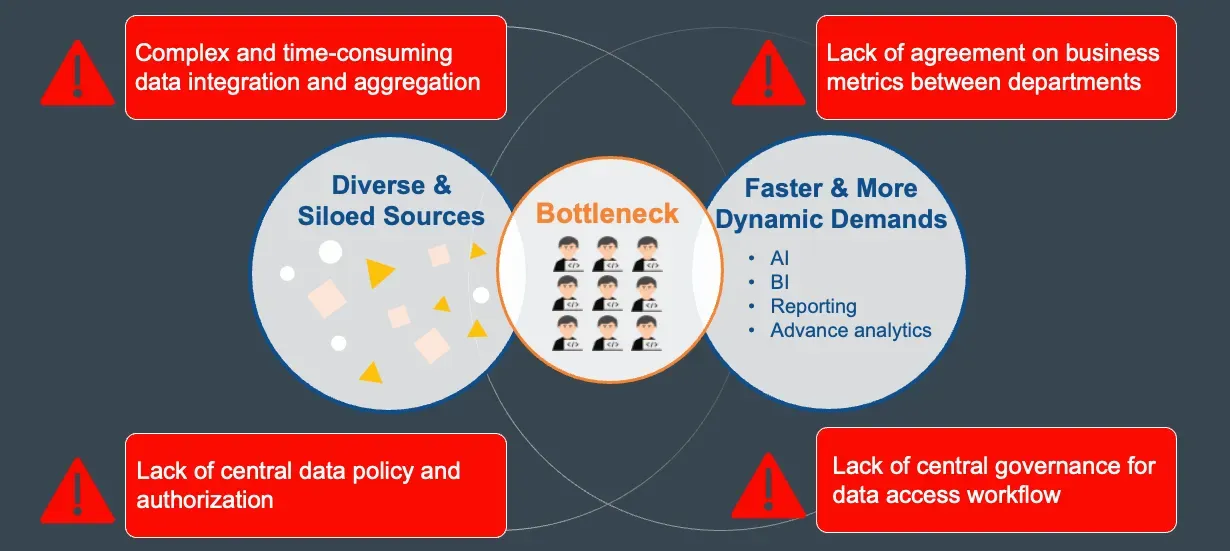
Two of the biggest bottlenecks: Sources and Application
Furthermore, with the rise of various data applications such as AI, ML, BI, and reporting, technical experts must handle different application scenarios and output format requirements. This means data teams still struggle to keep up with data demands.
Does LLM come to the rescue?
The emergence of LLMs demonstrates the ability of machines to understand natural language. These capabilities have empowered engineers to accomplish remarkable tasks, leading many to consider using LLMs to address the longstanding challenge of using natural language to retrieve data from databases, also known as “Text-to-SQL.”
Before the LLM era, researchers worked on various methods to address the challenges of converting text to SQL. Some earlier methods, like Seq2SQL and SQLNet, as well as more recent ones like HydraNet, PICARD, and SeaD, attempted to tackle these challenges. However, these earlier models still faced difficulties in generating complex queries and understanding the semantics of both natural language input and database schema.
With the introduction of “Retrieval Augmented Generation (RAG)” and advancements in LLM models, there is now an opportunity to combine LLM comprehension with RAG techniques to enhance the understanding of natural language, schema, and the capability to generate more complex query generation scenarios.
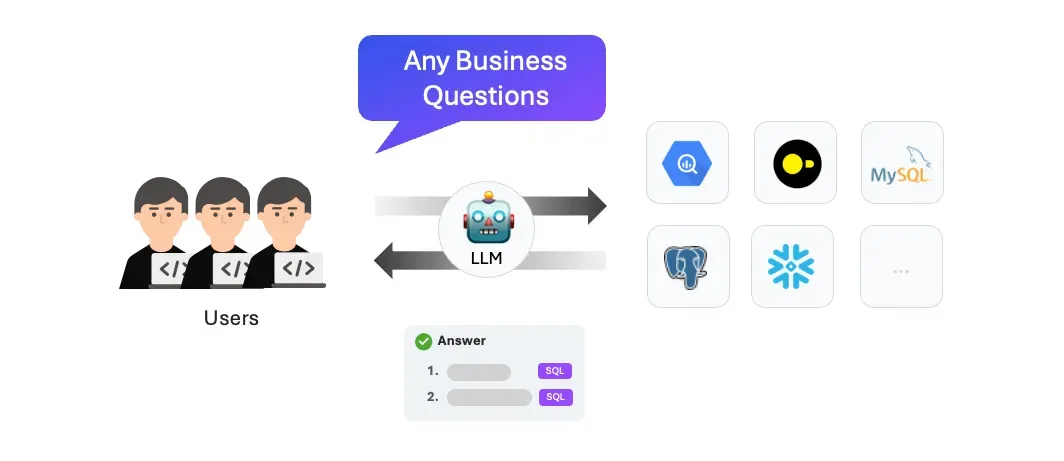
Ask any business question and get fast answers without worrying about the technical part.
The End Of Data Silos?
Modern data platforms like AWS, Snowflake, Databricks, and Starburst use proposed data architecture solutions, such as Data Fabric, to connect data from various sources and Data Mesh architecture to allow business teams and users to access data independently. These innovations standardize metadata across sources and ensure secure decentralized data ownership for domain users.
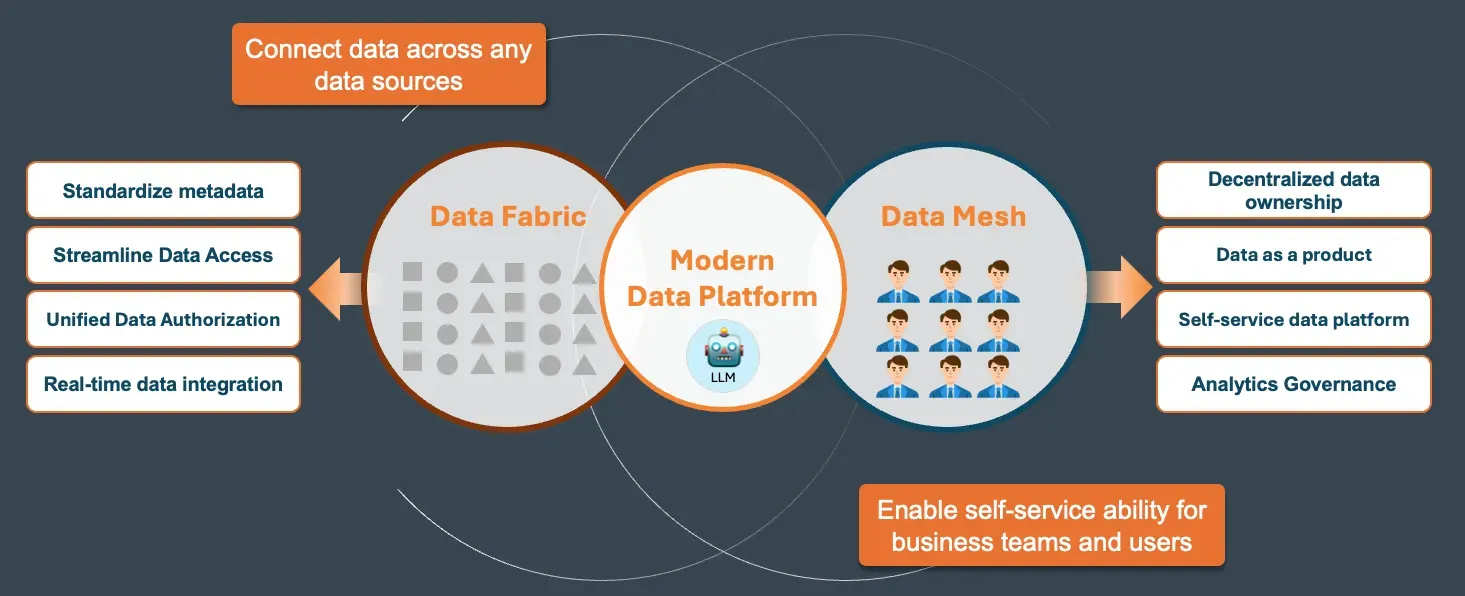
The Modern Data Platform
Despite these platforms centralizing data storage and enabling users to access data through their interfaces, organizations still face challenges in making data accessible. This includes providing semantic context such as calculations, metrics, and relationships and implementing access control and governance with different business user persona.
As the modern data platform becomes the foundation for more domain-specific data applications and AI agents, these applications and agents provide domain-specific business context, metrics, and application-level access control. This will help eliminate the barriers between data and business domain knowledge, potentially revolutionizing how businesses operate and make decisions.
Image from Emerging Architectures for Modern Data Infrastructure by a16z blog
As more companies adopt this architecture to mitigate data silo challenges, is this the end of data silos? Can we solve all the data silo challenges we mentioned earlier?
Emerging AI Agents In Different Verticals And Functions
One of the recent blog posts, “AI Agents are disrupting automation: Current approaches, market solutions and recommendations” from Insight Partners, has shown that the emergence of AI Automation tools, AI Agents/ Copilots has been booming in the past few months, and argued it will become the new norm in every industry across all departments in the following few years.
The AI Automation Market Cap from Insight Partners
Fragmented Design In Sources, Context, Administration
The post also presents an architectural diagram showing the design of an AI agent. Typically, an AI agent consists of several common components: user interface, AI pipeline, administrator, data connectors, and semantic search.
User Interface and AI Pipeline are what most AI agents differentiate; similar to traditional software development, most logics regarding administration, source connectors, and storage are similar.
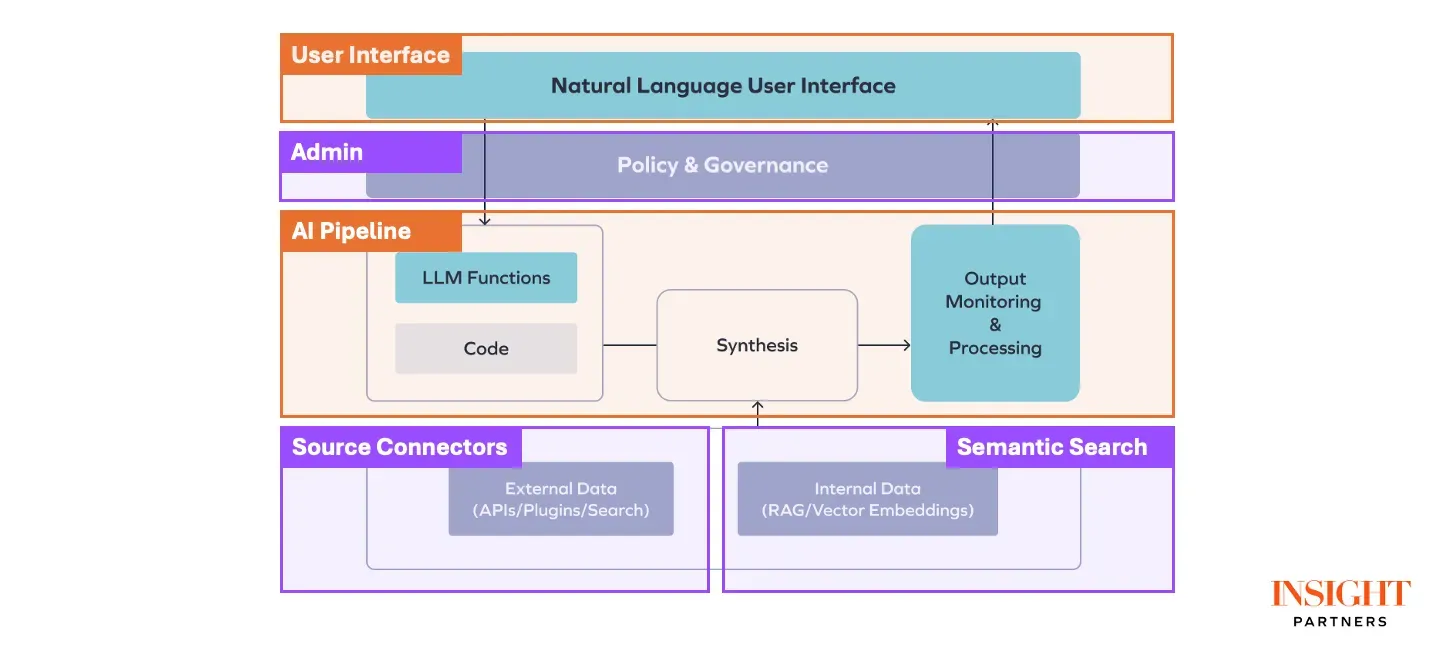
Common components within an AI agent
In today's AI systems, each agent develops its internal semantic context, connections, and controls to provide necessary context. As a result, it is currently not possible for agents to learn and share business logic learned from the company.
This creates a new challenge.
The New Silo, The AI Agent Silos
This month, the founder of Notion, Ivan Zhao, shares his thoughts on X about the challenges of the future AI/ LLM revolution. In the AI era, not only is data fragmented, but context is also fragmented. If using multiple AI agents is the definite future, this potentially creates new complexity for businesses operating multiple AI agents internally.

Image from Founder of Notion Ivan Zhao’s X post
There will be a new set of challenges in the upcoming years of the new AI era. Some critical issues that will arise include duplicate access control and policy settings across agents. When a business context changes, such as an altered KPI formula, it will be difficult to determine which agent uses the correct metrics or terminology to answer users’ questions. Ultimately, AI agents cannot be trusted because we cannot be certain whether a given agent accurately understands our questions.
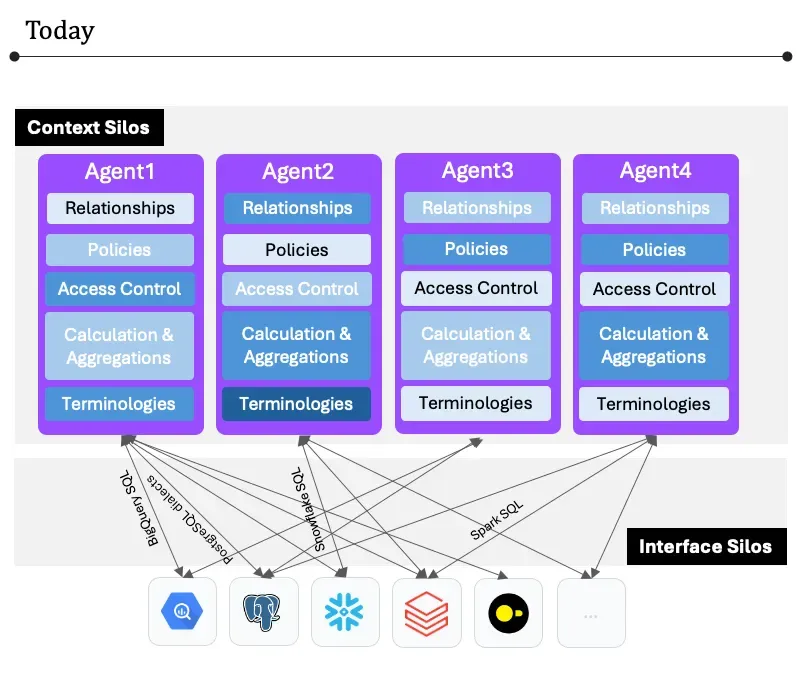
In today’s multi-AI agent architecture
Let’s break down the challenge into two major categories.
The Context Silos
The context within an agent usually includes the user’s persona, such as their role, permissions, and preferences, and the semantic context of the data, including relationships and hierarchies. By recognizing this information, the system can ensure that queries return contextually accurate results.
However, in today’s multi-AI agent architecture, this information is fragmented and repeatedly implemented in each AI agent without any method to facilitate communication and extract information from one another.
The Interface Silos
The second major challenge is that even though LLMs or AI agents help us deal with data silo SQL complexity(interface) challenges, each of the agents is implementing the interface communicating with the data sources in different approaches; these nuances are not exposed to end users. However, the discrepancy between each implementation can confuse users with each agent’s behaviors.
How Can We Solve It? The Wren AI Project
Given the two biggest challenges happening in today’s multi-AI agent architecture, we need a new layer to deal with it; providing a representation layer allows AI agents to understand and reuse definitions that are already well defined, and when any semantics are updated, all agents should get those latest information automatically.
The Semantic Engine for AI/ LLM Agents, Wren Engine
This is why we started Wren Engine, a semantic engine that brings business context and associated access information to AI agents. AI Agents can set up information such as semantic relationships, policies, access control, calculation and aggregations, and business terminology definitions with Wren Engine, so when the query requests are passed into Wren Engine, they will dynamically generate logical plans based on different user personas, and semantic context.
Each AI agent controls a specific sub-context and acts as an expert, while the Wren engine orchestrates all AI agent sub-contexts as below.
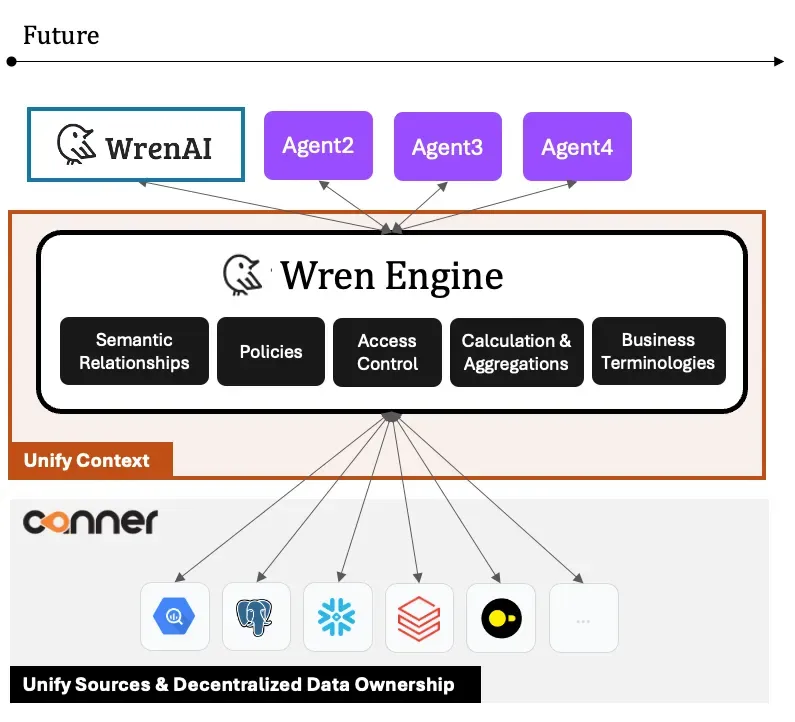
With the Wren Engine, we can standardize identical designs within each agent.
The LLM Interface Representation (LIR)
We’ve coined a new term called “LLM Interface Representation” (LIR), which sits between LLM Agents and your execution engines, such as Apache DataFusion, DuckDB, or even your existing databases and warehouses. The LIR between the LLM agents and the User Interface(SQL, API) provides business context, including business terminologies, concepts, data relationships, calculations, aggregations, and user access properties, to LLM agents and the execution engine.
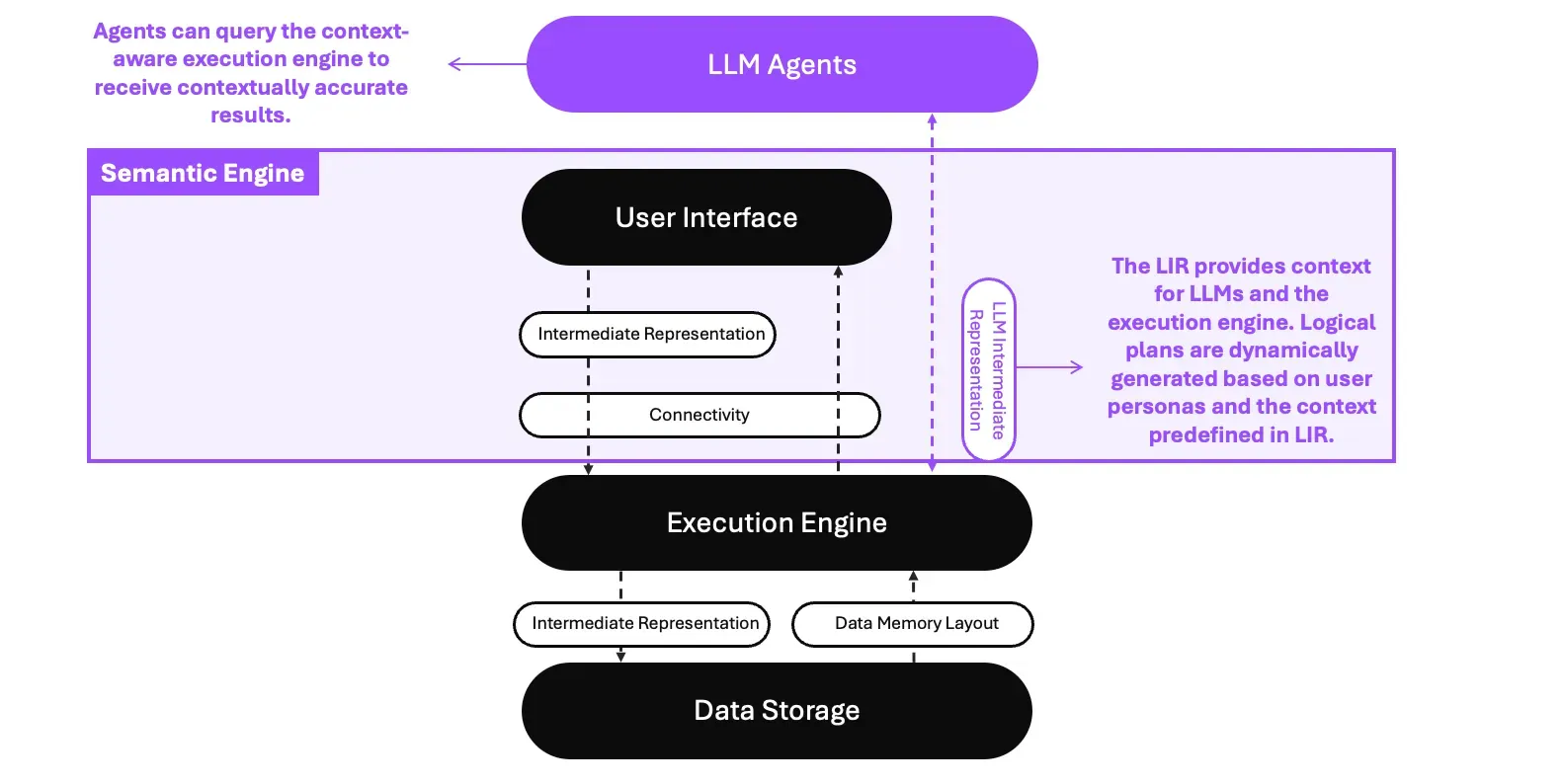
The new layer and LIR design
With this new design, we can achieve results below:
- Context to LLMs: We can provide the necessary context to LLMs, enabling them to understand the meaning of the data structure in the business and also setting up the right access control based on policy or governance role settings.
- Logical plan generation: When queries are sent from different user personas and contexts, it will dynamically generate the right logical plan for your execution engines. This is done based on the predefined semantic relationships, calculations, aggregations, access control, and policies in the LIR.
The Wren AI Project
Here’s a proven implementation of the concept described in the previous sections.
The Wren AI is the LLM agent built on top of the semantic engine — Wren Engine; within the Wren Engine, we’ve designed the LIR called the “Modeling Definition Language(MDL).”
The implementation has shown that the MDL could help bring the context to LLMs through the RAG architecture and predefined a context-aware layer in the logical plan during the query planning phase; the SQL queries passed into Wren Engine will dynamically generate logical plans based on different user personas, and semantic context provided by the MDL.
Check out our GitHub to learn our implementation!
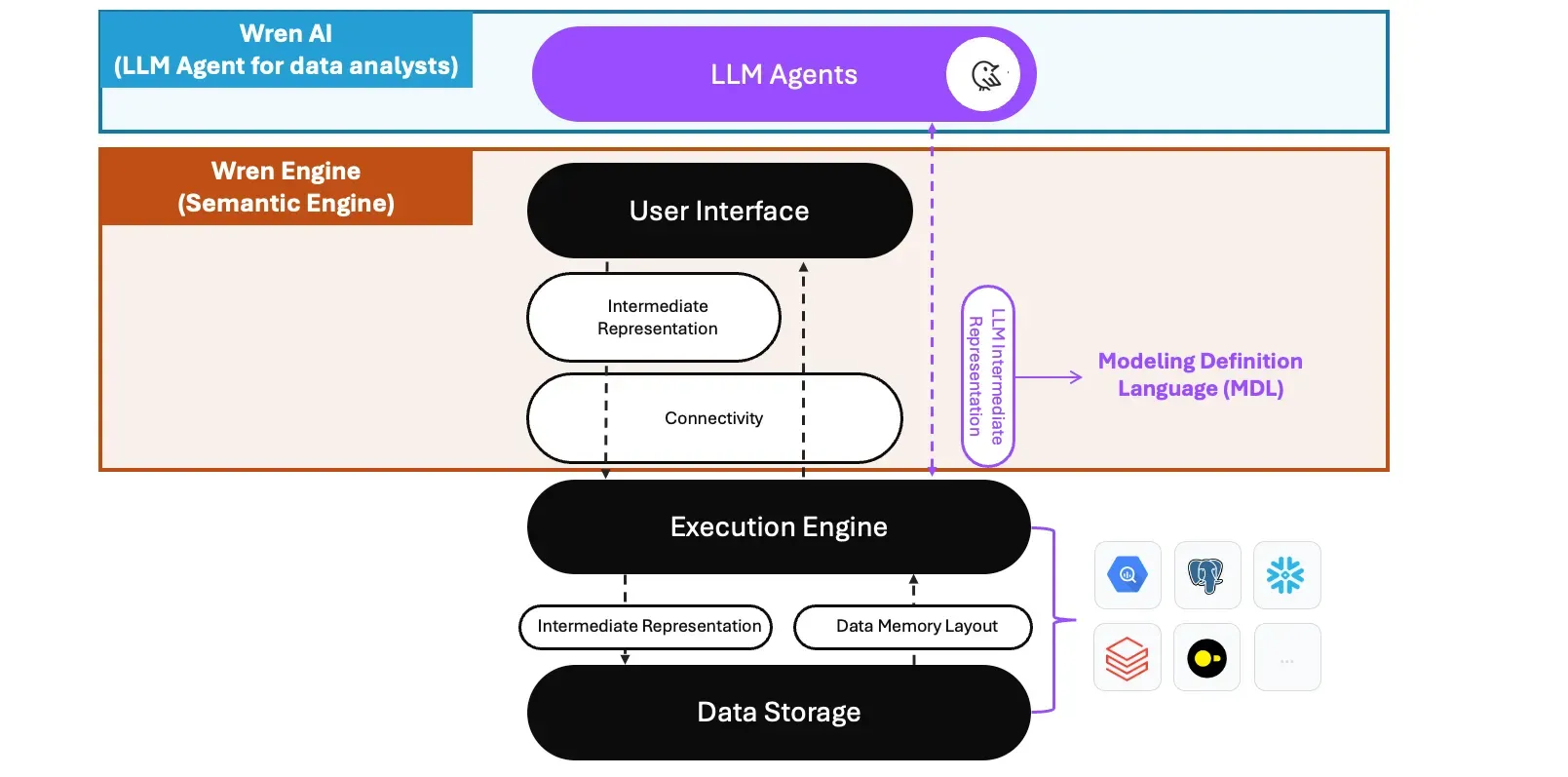
The Wren AI Project architecture
Open-source and Standard Interface to AI Agents
The Wren AI project is fully open-sourced on GitHub, which every LLM developer or user can host freely as the AI agent for ad-hoc and analytics use cases, with any LLM inference endpoints such as Ollama, OpenAI, and Fireworks AI, etc.; the Wren Engine can be the semantic engine for developing internal and external AI agents.
The Wren engine aims to build an agnostic semantic engine for any AI agent. It follows two important traits: Embeddable and interoperability. With these two designs in mind, you can reuse the semantic context across your AI agents through our APIs and connect freely with your on-premise and cloud data sources, which nicely fit into your existing data stack.
Thank you, Cheng Wu, Jimmy Yeh, Yaida Colindres help review the article and provide feedback!
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free TrialRelated Posts
Beyond Dashboards How Conversational AI is Revolutionizing Structured Finance Analytics
How Wren AI transforms complex financial data into instant, actionable insights through natural language, no technical expertise required
Jun 26, 2025How AI-Powered Analytics Transformed a Brokerage’s Trading Platform
GenBI Delivers 10x Faster Data Insights for Crypto Trading Firms Using Natural Language Queries
Apr 01, 2025Beyond Text-to-SQL: Why Feedback Loops and Memory Layers Are the Future of GenBI
How Wren AI’s Innovative Approach to Question-SQL Pairs and Contextual Instructions Delivers 10x More Accurate Generative Business Intelligence

Keep reading
 Insight
InsightBeyond Dashboards How Conversational AI is Revolutionizing Structured Finance Analytics
How Wren AI transforms complex financial data into instant, actionable insights through natural language, no technical expertise required
 Product
ProductHow AI-Powered Analytics Transformed a Brokerage’s Trading Platform
GenBI Delivers 10x Faster Data Insights for Crypto Trading Firms Using Natural Language Queries
 Insight
InsightBeyond Text-to-SQL: Why Feedback Loops and Memory Layers Are the Future of GenBI
How Wren AI’s Innovative Approach to Question-SQL Pairs and Contextual Instructions Delivers 10x More Accurate Generative Business Intelligence