How do you use LangChain to build a Text-to-SQL solution? What are the challenges? How to solve it?
In this post, using LangChain as an example of how you could use it to implement text-to-SQL, encounter challenges and how you can solve…

Howard Chi
Updated: Dec 18, 2025
Published: Aug 20, 2024

Note: this tutorial predates Agentic GenBI. The walkthrough below still works, but it frames Wren AI as a text-to-SQL tool. Today Wren AI is an agent that reasons over a governed context layer, with skills and memory, for humans and agents alike. Read "Introducing Agentic GenBI" to see how the product works now.
Retrieval-augmented generation (RAG) has opened up a new opportunity for LLMs to leverage their capability to comprehend users’ intentions to search internal database knowledge for SQL generation.
LLM frameworks such as LangChain and LlamaIndex provide tutorials to help developers implement text-to-SQL on their data sources. However, when these frameworks are deployed in production, users quickly find it challenging to implement the necessary features.
In this post, I’ll give a brief walkthrough using LangChain as an example of how you could use it to implement text-to-SQL. We will break down the challenges you will encounter and provide a solution to solve them.
How to do Text-to-SQL in LangChain?
This is based on the tutorial from LangChain's official documentation
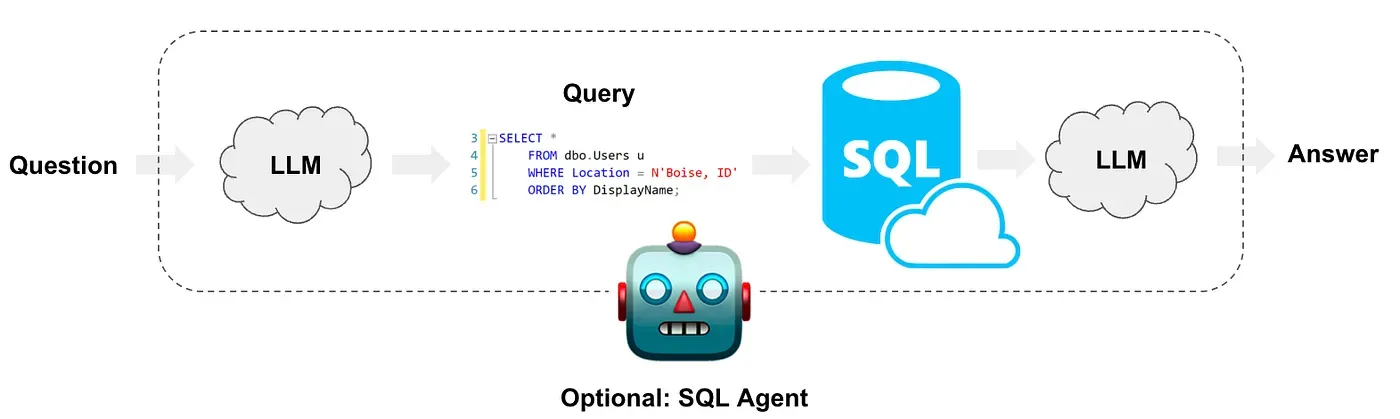
Image from LangChain Tutorial
Here’s a high-level concept of building a text-to-SQL solution in LangChain; check the full tutorial here.
Here’s how it works
First, when users ask a business question, LLM will comprehend the question and generate SQL based on DDL that comes along with the prompt with the business question; usually, if you want to enhance the semantics understanding, you will also attach semantics with the prompt.
First, install LangChain-related libraries
Next import SQLDatabase from langchain-community , SQLDatabase is an SQLAlchemy wrapper around a database, which provides a SQL Toolkit on top of databases.
Use create_sql_query_chain to generate different dialects of SQL languages.
Here’s an example of how the prompt looks like:
Here, we see we are asking LLMs to generate SQL based on a string template {dialect} ; the underlying mechanism is to insert the current dialect into the prompt and rely on LLMs to generate SQL dialects.
For {table_info} , you will need to insert all the table DDLs you want LLM to understand. What if you have many tables? We can’t dump the full information about our database in every prompt. LangChain's official tutorial suggests the following.
Simplify our model’s job by grouping the tables together.
You can group tables by categories:
Another common way is to store table schema in a vector database and perform a semantic search to retrieve relevant DDLs from certain business inquiries. However, many challenges remain when moving to production.
Challenges for LangChain building Text-to-SQL
Building a text-to-SQL tool using LangChain appears simple, but there are common challenges that arise when integrating it with production use cases. As listed below.
How do storing and defining business semantics in text-to-SQL retrieval work?
The problem with using text-to-SQL solely based on data schema is that when users ask business questions through the chat interface, they usually speak in business languages, not data structure definitions such as table names, column names, etc.
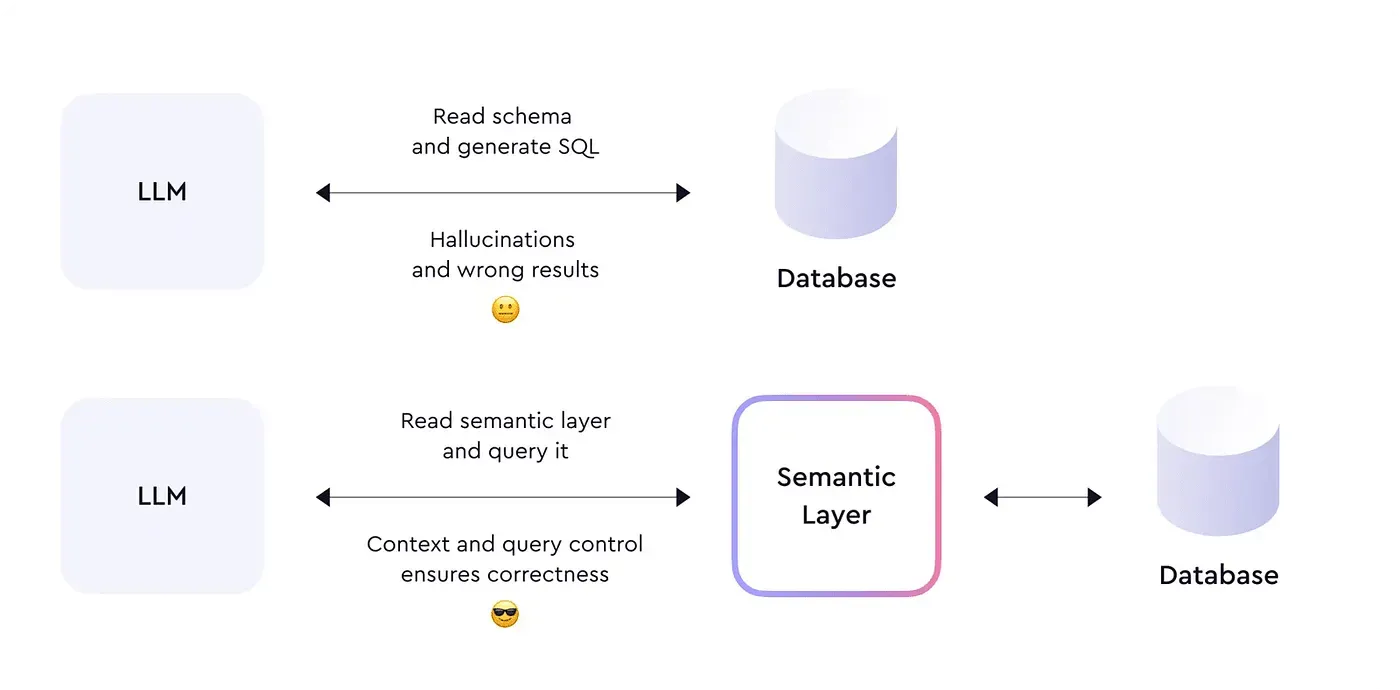
Image from cube.dev blog
When asking through AI, you might use your business terminologies and definitions, as well as relationships that are defined within your company, so you need to consider not only data structure but also semantics.
How do we optimize table schema and semantics stored in a vector database?
In the tutorial in LangChain, demonstrate putting all your table schema into the prompt. When you connect to production databases, the tables easily scale to thousands and tens of thousands of tables in a database.
You can’t fit all the tables into a prompt, so you need to embed the table and metadata from the metadata store into a vector database. When users ask a question, you can use semantic search in a vector database to retrieve the most relevant vectors from the vector database.
The process described above mostly operates offline, doing vector index creation. Pinterest has shared how they deal with the problem in their recent post about how they internally build text-to-SQL.
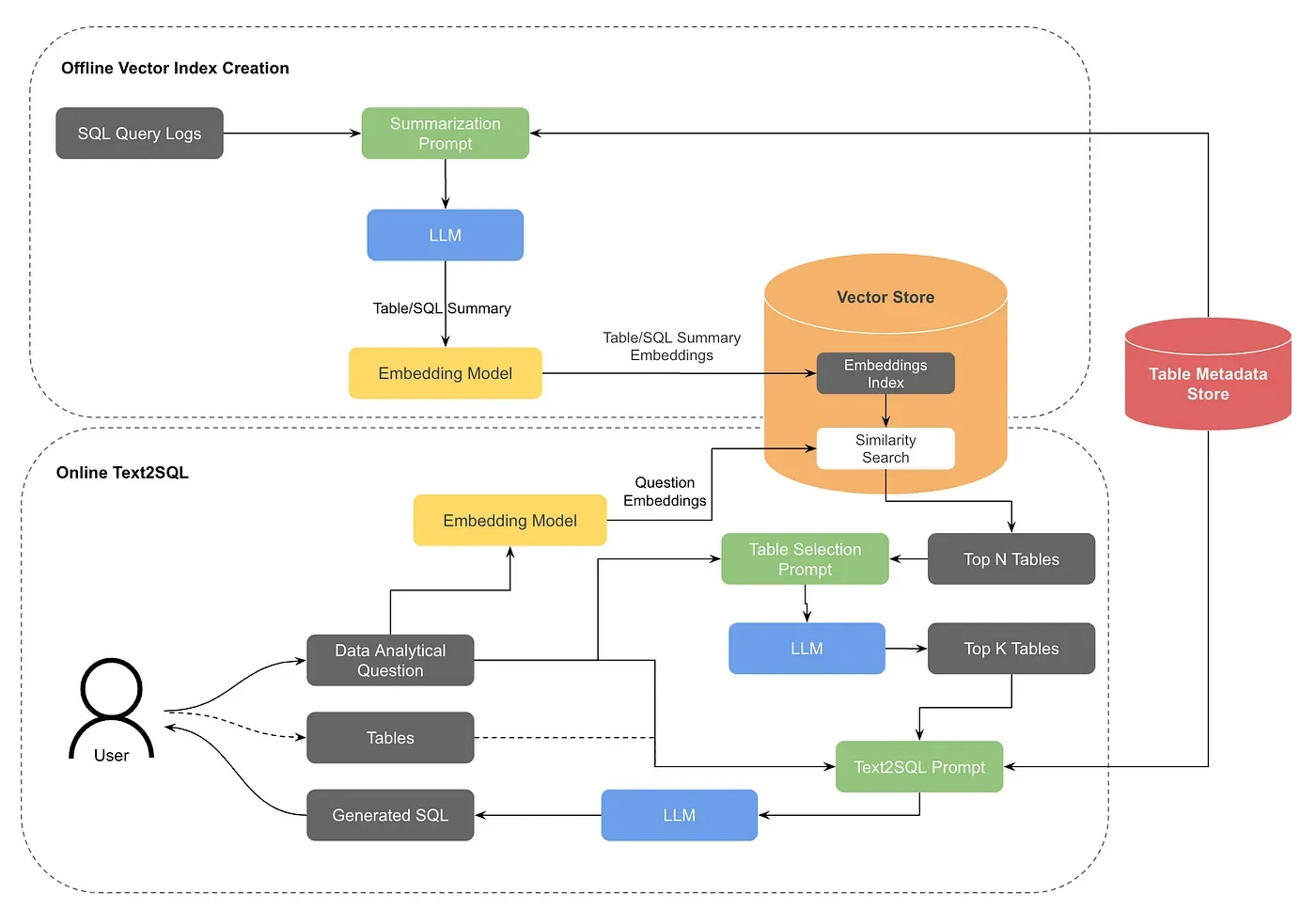
Image from “How we build text-to-sql at Pinterest”
Inconsistent data retrieval performance
Different databases need to speak in different dialects; LangChain’s Text-to-SQL tutorial relies on a popular Python library called SQLAlchemy , under the hood SQLAlchemy provides a standard toolkit and ORM for users to talk to different databases, but LLMs still need to generate certain dialects for different databases.
At first glance, using this pattern sounds reasonable and could easily provide LLM capability to many databases through SQLAlchemy.
When moving to production, using the same SQL syntax with predefined aggregations and calculations is important for better and consistent retrieval performance across data sources.
How can we solve it? Wren AI comes to the rescue!
I list above some obvious challenges to building a production-ready text-to-SQL solution. This is why our team builds Wren AI, the open-source AI data assistant for your databases. You can set up an AI agent internally for your text-to-SQL tasks within a few minutes.
Automation across metadata and semantics
Using Wren AI, we automate all the metadata and semantics and help LLMs learn how semantics work in their businesses without you writing any code. with your user-friendly interface, you can model your data schema and add business semantics to the modeling layer. We will automatically complete all the offline Vector Index creation for you.
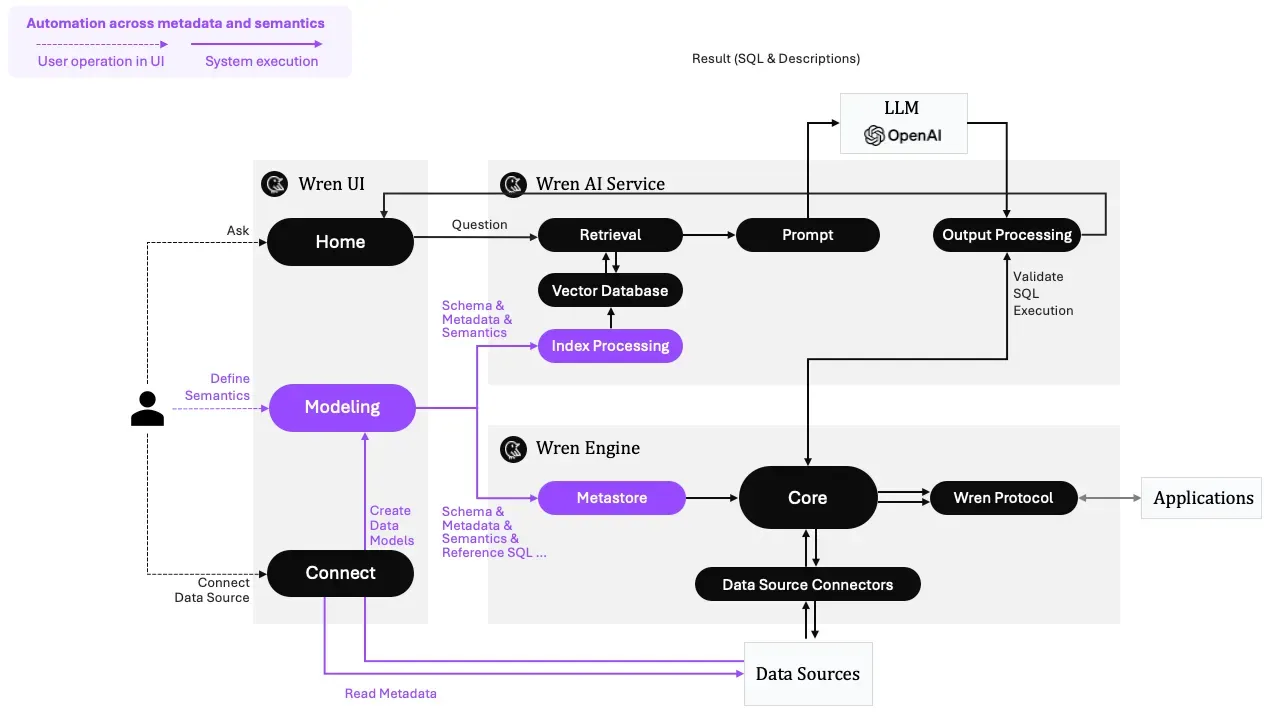
Automation across UI, AI service, and semantic engine
Optimize semantic search and prompt engineering.
Mapping table schema with semantics and ensuring you can get the right information through prompt and semantics requires a lot of fine-tuning; with Wren AI, we handle all the optimization and ensure it can search for the most relevant result when users ask business questions.
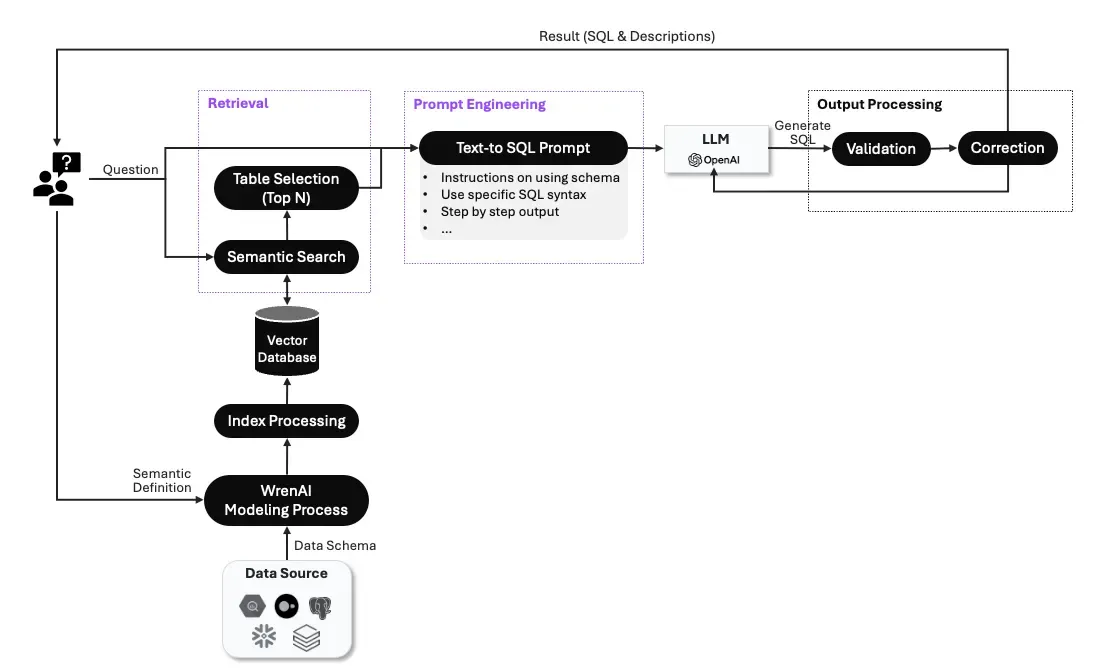
Wren AI optimizes retrieval and prompts out-of-the-box
Consistent SQL syntax across multiple sources
Underlying Wren AI, we developed a semantic engine called Wren Engine, which is also open-sourced. The engine can transpile from Standard ANSI SQL into different SQL dialects and provides the semantic encapsulate ability to define aggregations and calculations in the semantic modeling layer.
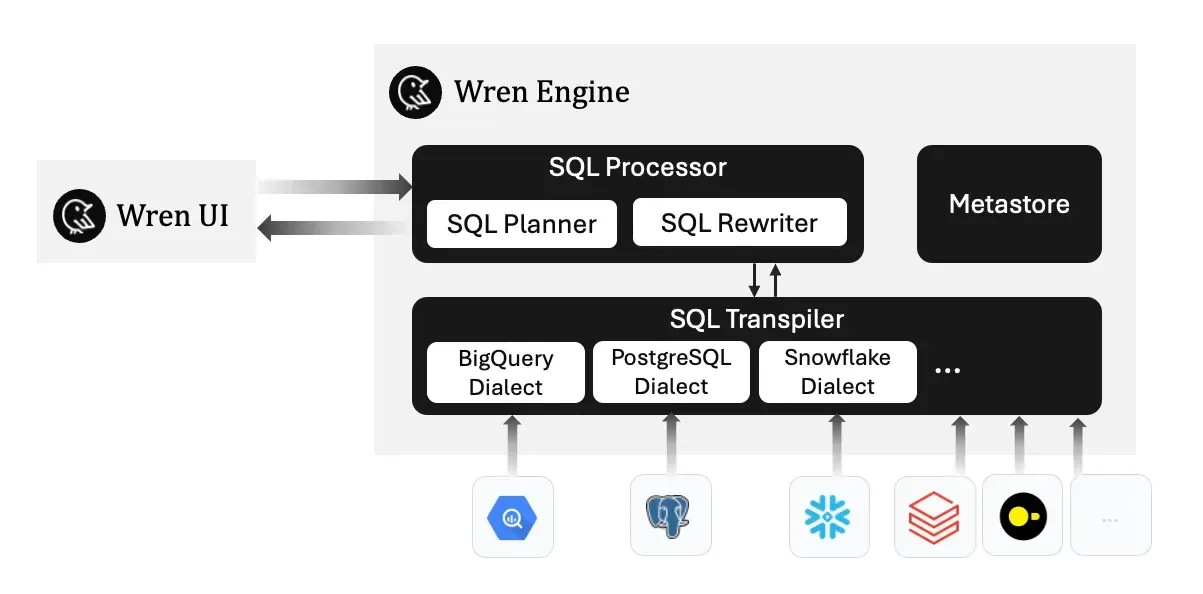
Wren Engine Architecture
Feedback loop design
The feedback loop is one of the most important designs for AI agents. We want our agent to learn from our history and also teach the agent to perform better in future tasks; this is where the feedback loop comes in.
We built in a Wren AI feedback loop in the user interface, so when you ask a question and get the answer from Wren AI, you can provide adjustments to the agent, will learn from your inputs, regenerate the result, and store the learning in the semantic modeling definition, so it will generate the right outcome when users ask the next time.
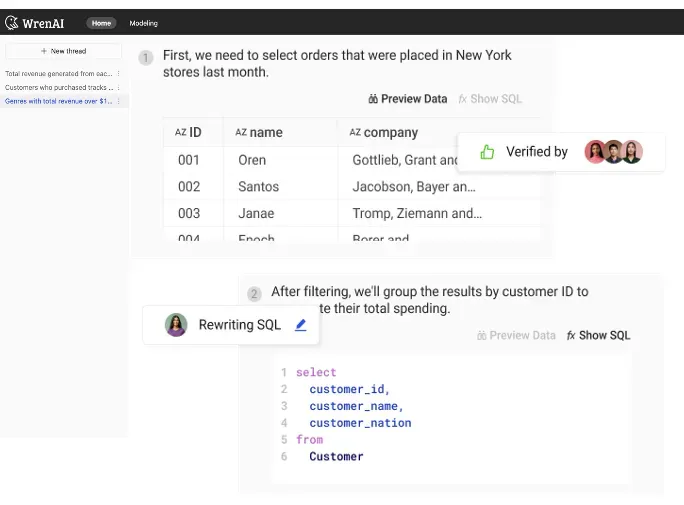
Wren AI is a fully open-source project! It’s on GitHub; check it out now!
🚀 GitHub: https://github.com/canner/wrenai
🙌 Website: https://www.getwren.ai/
Don’t forget to give ⭐ Wren AI a star on Github ⭐ if you’ve enjoyed this article, and as always, thank you for reading.
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free TrialRelated Posts
Beyond Dashboards How Conversational AI is Revolutionizing Structured Finance Analytics
How Wren AI transforms complex financial data into instant, actionable insights through natural language, no technical expertise required
Mar 31, 2025Fueling the Next Wave of AI Agents Building the Foundation for Future MCP Clients and Enterprise Data Access
How Wren Engine Powers the Semantic Layer for AI-Driven Workflows, Unlocking Context-Aware Intelligence Across the MCP Ecosystem
Apr 01, 2025Beyond Text-to-SQL: Why Feedback Loops and Memory Layers Are the Future of GenBI
How Wren AI’s Innovative Approach to Question-SQL Pairs and Contextual Instructions Delivers 10x More Accurate Generative Business Intelligence

Keep reading
 Insight
InsightBeyond Dashboards How Conversational AI is Revolutionizing Structured Finance Analytics
How Wren AI transforms complex financial data into instant, actionable insights through natural language, no technical expertise required
 Product
ProductFueling the Next Wave of AI Agents Building the Foundation for Future MCP Clients and Enterprise Data Access
How Wren Engine Powers the Semantic Layer for AI-Driven Workflows, Unlocking Context-Aware Intelligence Across the MCP Ecosystem
 Insight
InsightBeyond Text-to-SQL: Why Feedback Loops and Memory Layers Are the Future of GenBI
How Wren AI’s Innovative Approach to Question-SQL Pairs and Contextual Instructions Delivers 10x More Accurate Generative Business Intelligence