How we design our semantic engine for LLMs? The backbone of the context layer for LLM architecture.
The advent of Trend AI agents has revolutionized the landscape of business intelligence and data management. In the near future, multiple…

Howard Chi
Updated: Dec 18, 2025
Published: Aug 20, 2024

The advent of Trend AI agents has revolutionized the landscape of business intelligence and data management. In the near future, multiple AI agents will be deployed to harness and interpret vast amounts of internal knowledge stored within databases and data warehouses. To facilitate this, a semantic engine is crucial. This engine will map data schemas to the relevant business context, enabling AI agents to comprehend the underlying semantics of the data. By providing a structured understanding of the business context, the semantic engine will empower AI agents to generate accurate SQL queries tailored to specific business needs, ensuring precise and context-aware data retrieval.
The problem of LLMs with data structures?
Enabling AI agents to talk directly to the database. The underlying technology provides an interface for transforming natural language to SQL and querying the databases.
However, mapping schema with context from databases isn’t a simple task. It is not enough to merely store schema and metadata. We need to delve deeper into understanding and processing the data.
Lack of semantic context
When you enable LLMs directly on top of databases, you can rely on DDL information already in the databases to help LLMs learn your database structure and types. You may also add titles and descriptions based on the provided DDL to help LLMs understand the definitions of each table and column.
In order to achieve optimal performance and accuracy from LLMs, simply having DDL and schema definitions is not sufficient. LLMs need to comprehend the relationships between various entities and understand the calculation formulas used within your organization. Providing additional information such as calculations, metrics, and relationships (join paths) is essential for helping LLMs understand these aspects.
Lack of interface definitions between LLMs and semantics
As mentioned in the previous section, it is important to have a semantic context that allows LLMs to understand the intricacies of calculations, metrics, relationships, etc. We need definitions to generalize subjects that we face as below.
Calculations
Pre-trained LLMs have their agenda for each terminology, and it’s not how each company defines its own KPI or formulas. Calculations are where we provide definitions such as Gross profit margin equals (Revenue, Cost of Goods Sold) / Revenue LLMs might already be powerful enough to understand common KPIs such as Gross Profit Margin, Net Profit Margin, CLTV, etc.
However, in the real world the columns are usually messy, and revenue might be set as column name rev , and we will probably see rev1, pre_rev_1, rev2, etc.. LLMs have no way of understanding what they mean without semantic context.
Metrics
“Slice and dice” is a technique used in data analysis, particularly in the context of multidimensional data, to break down and view data from different perspectives. This approach helps explore and analyze data in more detail.
Such as the Sales Metrics examples:
- Total Sales: Total revenue generated over a specific period.
- Sales by Region: Sales data segmented by geographical regions.
- Sales by Product: Sales data segmented by individual products or product categories.
- Sales by Channel: Sales data segmented by different sales channels (e.g., online, retail, wholesale).
Another example using Customer Metrics:
- Customer Demographics: Breakdown of customers by age, gender, location, etc.
- Customer Segmentation: Categorizing customers based on behavior, purchase history, and preferences.
- Customer Acquisition: Number of new customers acquired in a specific period.
- Customer Churn Rate: Percentage of customers who stop doing business with the company.
Semantic Relationships
Semantic relationships are not the same as primary and foreign keys, though they are related concepts within the context of databases and data management.
A semantic relationship refers to the meaningful connection between different pieces of data, often based on their real-world relationships. These relationships describe how data elements relate to each other conceptually, beyond just the structural links provided by primary and foreign keys; for example, The semantic relationship between Customers and Orders tables could be described as “A customer can place multiple orders.” This captures the real-world meaning of the relationship beyond just the technical linkage.
On the other hand, primary and foreign keys are used to enforce data integrity and establish relationships at the database schema level. Semantic relationships are used to describe and understand how data entities are related in a broader context, which you can also define one-to-many, many-to-many , one-to-one relationships that are not available in primary and foreign key settings.
Challenges in Integrating LLMs with Heterogenous Data Sources
Unstable SQL Generation Performance
Connecting multiple data sources and expecting LLMs to seamlessly handle different SQL dialects presents a significant challenge: ensuring performance consistency across diverse sources. This challenge becomes even more pronounced as the number of data sources increases. Consistency is key to building trust in AI systems. Ensuring stable performance is directly tied to the overall usability and reliability of your AI solutions.
Inconsistent Access Control
Different data sources often come with their own access control mechanisms. When these sources are directly connected, maintaining a consistent data policy becomes difficult, which is crucial for large-scale data team collaboration. To address this issue, a central governance layer is essential for managing access control across all LLM use cases. This layer ensures that data policies are uniformly enforced, enhancing security and compliance across the organization.
The advent of the context layer
Directly connecting to multiple data sources presents significant challenges in consistency and performance. A more effective approach is to implement a context layer for LLM use cases.
What is a Semantic Layer?
The core concept behind Semantic Architecture is the *ontology*. An ontology is a formal representation of a domain comprising classes that represent entities and properties and their relationships to other entities.
By providing an ontology for the domain of a dataset, LLMs gain an understanding of not only how to present the data but also what the data represents. This enables the system to process and even infer new information that is not explicitly stated within the dataset.
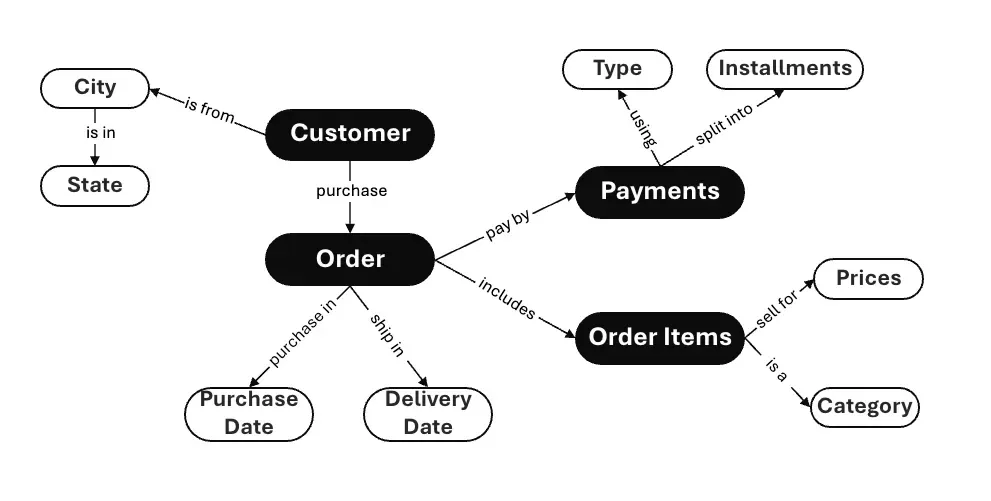
Benefits of a Semantic Layer
A context layer does more than just help AI agents understand the semantics between different domains, entities, and relationships. It also offers a framework for AI agents to:
- Calculate using the correct formulas
- Provide context for join paths and metrics
- Provide a standardized SQL layer that ensures consistency across different data sources.
- Apply encapsulated business logic and manage complex relationships between entities at runtime.
Implementing a context layer thus enhances the ability of AI agents to deliver accurate and consistent insights by bridging the gap between diverse data sources and complex business contexts.
The Wren Engine — The Semantic Engine for LLMs
This is why we designed Wren Engine, the semantic engine for LLMs, which aims to solve the challenges we laid out.
Using Wren Engine we defined a “Modeling Definition Language” (MDL), to provide context and proper semantics metadata to LLMs, and the engine could use the MDL to rewrite SQL based on different user persona, and semantic data modeling methods. With the engine, build solutions on top of it such as access control, governance which usually reside in context layer.
Semantic Data Modeling
The fundamental concept of ontology involves designing a graph-structured representation of both metadata and data, commonly referred to as a knowledge graph. With the Wren Engine, you can define your data models and metrics within this graph-based architecture. This allows you to specify how columns in different models are related and what those relationships mean. Such a structured definition not only clarifies data relationships but also enhances the ability to rewrite SQL queries accurately and efficiently.
Semantic naming and descriptions
In the MDL, you can easily define semantic naming, and description in any model, column, view, and as well as relationship. With the semantic definitions, you can help LLM to understand the semantic meanings of the data structure.
Support runtime SQL rewrite with relationship and calculations
With Wren Engine you can design the semantic representations, with the “Modeling Definition Language”, we also build a user interface around it in our AI application Wren AI, which is also open source here. Behind Wren AI, the relationships between different entities, and declare in one-to-many , many-to-one , one-to-one could all be defined.
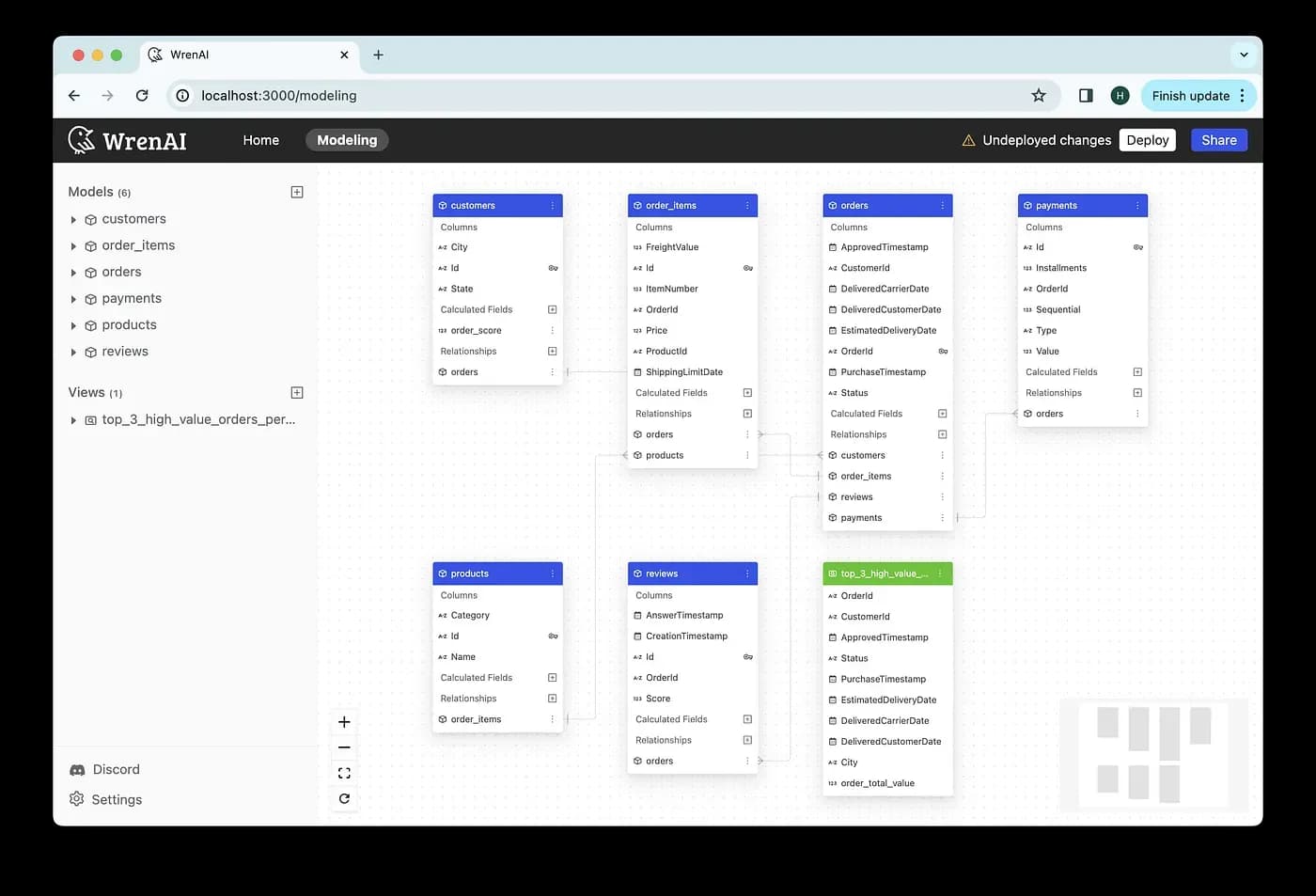
Below is a simple example of how you could define relationships
A relationship is made up of:
name: The name of the relationship.models: The models associated with this relationship. Wren Engine only associates 2 models in a relationship.joinType: The type of a relationship. Typically, we have 4 kinds of the relationship between 2 models: ONE_TO_ONE (1–1), ONE_TO_MANY (1-M), MANY_TO_ONE (M-1), MANY_TO_MANY (M-M).condition: The join condition between the two models. The Wren Engine serves as the join condition during SQL generation.
In models, you can also add custom calculations into calculations (expressions).
Support reusable calculations and function-like macros
About Calculations
Wren Engine provides the calculated field to define a calculation in the model. A calculation can use a defined column in the same model or a related column in another model through a relationship. Typically, a common metric is related to many different tables. Through calculated fields, it is easy to define a common metric that interacts between different models.
For example, below is a defined model called orders with 3 columns. To enhance the model, we may want to add a column called customer_last_month_orders_price to know the growth of every customer. We can define a calculated field like
About Macro Function
Macro is a template feature for Modeling Definition Language (MDL). It’s useful for simplifying your MDL or centralizing some key concepts. Macro is implemented by JinJava, which is a template engine in JVM that follows the specification of Jinja. With Macro, you can define a template to consume certain parameters and use it in any expression.
In below scenario, twdToUsd represents a universal concept across the entire MDL. Conversely, revenue and totalpriceUsd embody partial concepts specific to individual models.
Support of standard SQL syntax
Wren Engine has build in SQL processor and transpiler, through the Wren Engine we will parse the SQL that query to Wren Engine and then unpack and translate from WrenSQL syntax, which is complied with standard ANSI SQL, into different dialects such as BigQuery, PostgreSQL, Snowflake, etc.
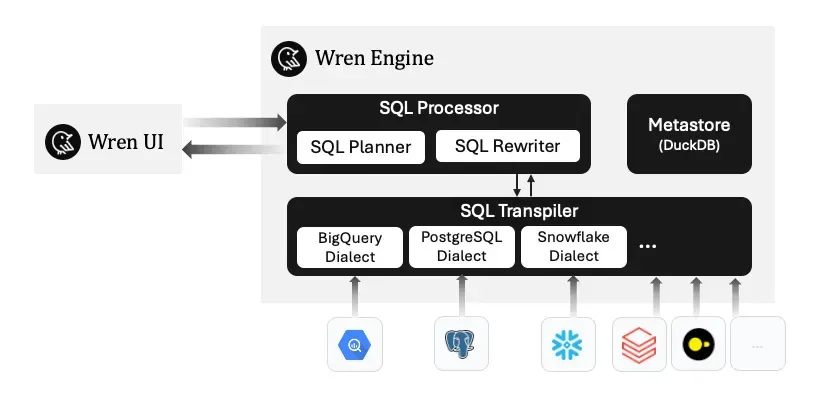
Wren Engine Architecture
Below is a simple example: here you define an MDL for your datasets; when you submit your SQL, all the relationships, calculations, and metrics will transpile into target dialect-specific SQL.
Here’s a example of a MDL file (please check on Gist)
If you submit query as below
The Wren Engine will transform Wren SQL based on MDL definition in dialect-specific SQL as below.
Consistent access control across sources
Managing access control across various data sources can be challenging due to differing access control mechanisms. Wren Engine also aims to solve problems such as
- Defining Data Policy: Ensures that all data sources adhere to the same security and access protocols.
- Unified Authentication and Authorization: By integrating different data sources under a single engine, authentication and authorization processes become streamlined. This uniformity reduces the risk of unauthorized access and ensures that users have consistent access permissions across all data sources.
- Role-Based Access Control (RBAC): Implementing RBAC, where access permissions are assigned based on roles rather than individual users.
We will share more about the details when we implement the project!
Open & Standalone architecture
Wren Engine is open sourced and it is design as a standalone semantic engine, which you can easily implement with any AI agents, you can use it as a general semantic engine for the context layer.

Final remarks
Wren Engine’s mission is to serve as the semantic engine for LLMs, providing the backbone for the context layer and delivering business context to BI and LLMs. We believe in building an open community to ensure the engine’s compatibility with any applications and data sources. We also aim to provide an architecture that allows developers to freely build AI agents on top of it.
If you are interested in Wren AI and Wren Engine, check out our GitHub. It’s all open-sourced!
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free TrialRelated Posts
Transform Your Database Management with an AI-powered spreadsheet-like Interface
Operate your database effortlessly using natural language, no SQL required.
Apr 21, 2025Powering AI-driven workflows with Wren Engine and Zapier via the Model Context Protocol (MCP)
Use semantic understanding, SQL generation, and email automation to streamline data requests with LLM agents and Wren’s powerful query engine.
Apr 11, 2025Powering Semantic SQL for AI Agents with Apache DataFusion
Bridge the Gap Between AI and Enterprise Data with a High-Performance Semantic Layer and Unified SQL Interface for Model Context Protocol (MCP)

Keep reading
 Product
ProductTransform Your Database Management with an AI-powered spreadsheet-like Interface
Operate your database effortlessly using natural language, no SQL required.
 Product
ProductPowering AI-driven workflows with Wren Engine and Zapier via the Model Context Protocol (MCP)
Use semantic understanding, SQL generation, and email automation to streamline data requests with LLM agents and Wren’s powerful query engine.
 Insight
InsightPowering Semantic SQL for AI Agents with Apache DataFusion
Bridge the Gap Between AI and Enterprise Data with a High-Performance Semantic Layer and Unified SQL Interface for Model Context Protocol (MCP)