Reducing Hallucinations in Text-to-SQL Building Trust and Accuracy in Data Access
How Schema Grounding, Semantic Layers, and Iterative Validation Can Enhance Text-to-SQL Reliability

Howard Chi
Updated: Dec 18, 2025
Published: Jan 07, 2025

Text-to-SQL systems promise a future where anyone, technical or not, can interact with data through natural language. Picture a marketing manager asking, “What was our top-selling product line last quarter?” and getting an immediate, accurate response without writing SQL. The potential to democratize data access is immense. It can liberate teams from data silos, speed up decision-making, and foster a more data-driven culture across organizations.
However, achieving this ideal state isn’t trivial. One of the most persistent challenges is the phenomenon of “hallucinations.” Within the world of large language models (LLMs) and text-to-SQL solutions, hallucinations occur when the system returns queries that reference nonexistent tables or columns, invents metrics, or produces logically incorrect constraints. The model might be confident, and the SQL might even look syntactically correct, but the query doesn’t align with your actual database schema or semantic definitions. The result is wasted time, eroded trust, and potentially misguided decisions.
In this article, we’ll explore why hallucinations occur in text-to-SQL, their real-world consequences, and the techniques that can help reduce them. We’ll also highlight how Wren AI tackles these issues through a holistic approach that includes schema awareness, iterative validation, semantic modeling with its Metadata Definition Language (MDL), and continuous feedback loops. While we’ll discuss Wren AI’s contributions, the principles here apply widely to any organization looking to improve reliability and trust in text-to-SQL solutions.
Defining Hallucinations in Text-to-SQL
A “hallucination” is when a model produces output not grounded in the provided context or facts. For text-to-SQL tasks, this means the system generates SQL queries that reference columns, tables, or filters that don’t exist. For instance, consider a database with a single sales table containing product_id, units_sold, and sale_date. A hallucinated query might look like:
SELECT product_name, revenue FROM sales WHERE region = 'EMEA';
product_name, revenue, and region aren’t in the schema. The model fabricated them because it associated these terms with typical sales-related queries without checking against the actual database structure.
Why Do Hallucinations Occur?
Hallucinations primarily arise because large language models (LLMs) generate text based on patterns, not schema awareness. Key factors include:
- Lack of Schema Grounding: Without explicit, up-to-date schema information, the model guesses columns or tables.
- Over-Generalization from Training: Models may rely on patterns seen in training data that don’t fit your database.
- Underspecified Queries: Vague or ambiguous user questions invite the model to “fill in the gaps.”
- Unconstrained Creativity: If not reined in, the model’s generative capabilities can produce plausible-sounding but invalid queries.
The Real-World Impact of Hallucinations
When hallucinations occur regularly, the consequences can be severe:
- Eroded Trust: Users quickly lose confidence if the system consistently produces nonsense.
- Wasted Resources: Technical staff must diagnose bad queries, negating the productivity gains text-to-SQL promises.
- Misguided Decisions: A query that slips through validation might lead to incorrect insights and poor strategic choices.
Foundations for Reducing Hallucinations
To minimize hallucinations, focus on “grounding” the model’s output in actual schema and semantic rules:
- Schema Provisioning: Always provide the model with your database schema.
- Validation Steps: Integrate layers of checks before showing a query to the user.
- Iterative Reasoning: Encourage the model to break down its reasoning to catch inconsistencies early.
Techniques to Minimize Hallucinations
A combination of strategies can significantly reduce hallucinations.
Schema Clarity and Explicit Definitions
- Detailed Schema Documentation: Enumerate all tables, columns, data types, and relationships.
- Contextual Metadata: For ambiguous column names, provide context. For example, clarify cust_id as “customer identifier,” helping the model map queries correctly.
Retrieval-Augmented Generation (RAG)
- On-Demand Schema Provision: Dynamically fetch schema details at query time. The model works with fresh, accurate information, leaving less room for guesswork.
- Query Blueprints: Keep a repository of template queries. Rather than inventing new patterns, the model adapts proven ones.
ReAct (Reasoning + Acting) and Chain of Thought (CoT) techniques
- Improved Query Accuracy: CoT guides the model to break down complex SQL queries step by step, reducing errors in query generation.
- Dynamic Error Handling: ReAct allows the model to reason through query errors and iteratively refine SQL commands, ensuring more accurate outputs.
- Complex Query Generation: By combining reasoning (CoT) with real-time actions (ReAct), the model can handle multi-step queries and nested SQL logic more effectively.
- Adaptive to Schema Variations: ReAct can interact dynamically with database schemas, adapting the query to schema changes or ambiguities.
Fine-Tuning on Domain-Specific Data
- Domain-Specific Training: Show the model examples of correct queries against your schema. Fine-tuning aligns the model’s understanding with real-world data structures.
- Incremental Updates: Continually refresh training as your schema changes, ensuring the model stays current.
Guardrails, Query Validation, and Dry-Runs
- Schema Validation: Automatically check if all columns and tables referenced by the generated SQL exist.
- Semantic and Syntax Checks: Use SQL parsers to confirm the query is syntactically valid.
- Dry-Run Execution: Before showing results to the user, attempt running the query against a test instance or in a safe mode. If the database returns errors (e.g., unknown column), prompt the system to correct itself. Dry-running catches hallucinations at the source, as it forces the model to align with actual database feedback.
Encouraging Transparency and Explainability
- Chain-of-Thought Prompting: Ask the model to articulate its reasoning steps internally.
- User Review: Optionally display a reasoning summary for advanced users, allowing them to verify the query logic.
Introducing Wren AI
Before we dive deeper into how Wren AI tackles hallucinations, let’s briefly introduce what Wren AI is and why it matters.
Wren AI is a text-to-SQL solution designed to bridge the gap between non-technical users and complex data ecosystems. Its goal is to enable anyone (analysts, product managers, marketing leads, executives) to ask questions in plain language and get accurate, meaningful answers from their databases. Wren AI stands out by blending powerful large language model (LLM) capabilities with structural safeguards, semantic modeling, and iterative feedback loops. This combination transforms raw SQL querying into a more natural, intuitive experience without sacrificing correctness.
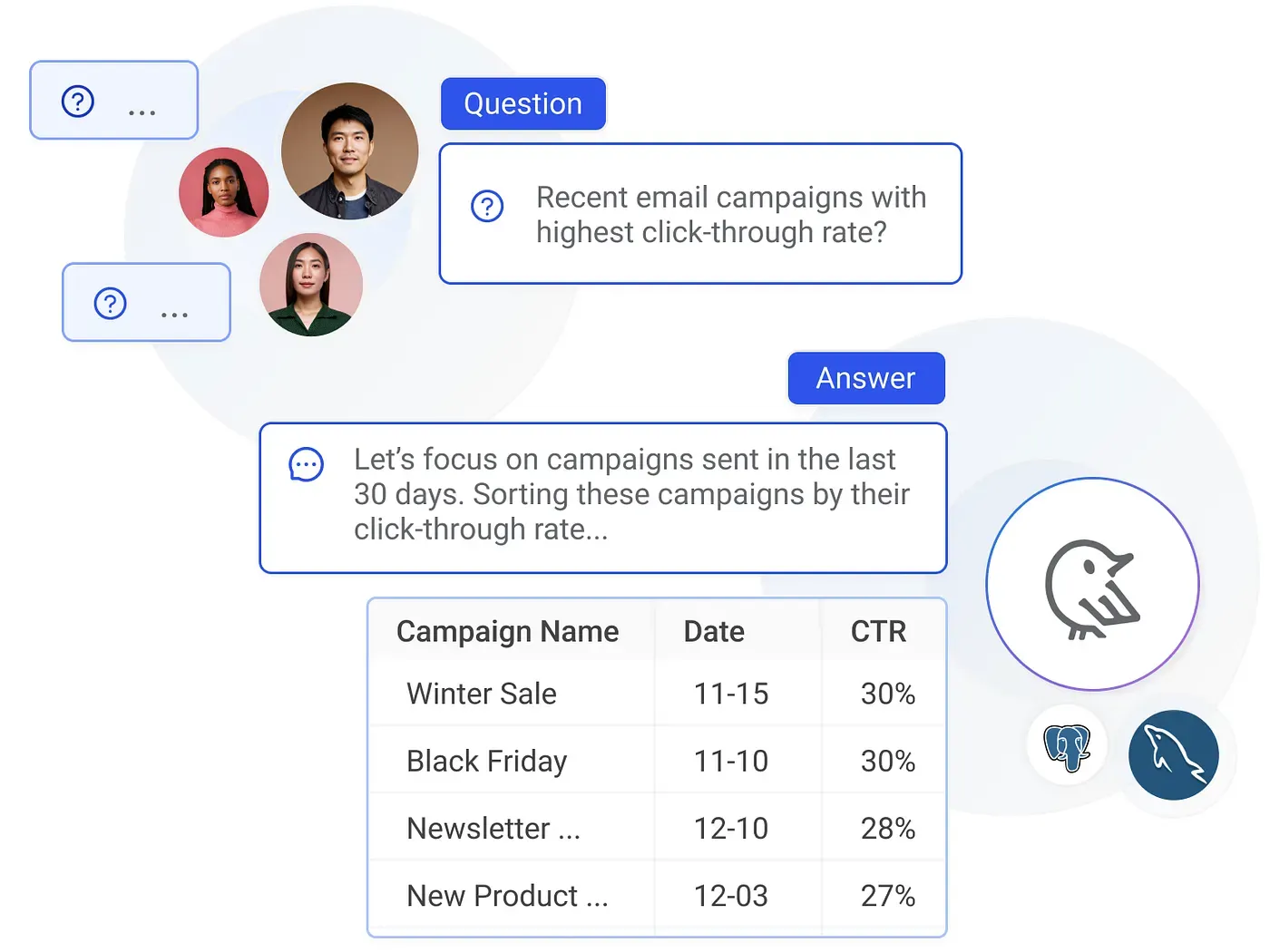
Where many text-to-SQL systems struggle with hallucinations and brittle logic, Wren AI adopts a holistic approach. From schema-first context provision to semantic layers defined by MDL, from transparent reasoning steps to dry-run validation, Wren AI ensures that the answers you get are grounded in your actual data and business definitions.
The Role of the Semantic Layer and MDL
While schemas define the physical structure of your data, organizations often need a higher-level context layer that encodes business meaning. This context layer ensures that everyone, from data engineers to business analysts, interacts with data consistently. Instead of every user interpreting raw fields in their own way, the context layer provides a canonical model of the data domain. It defines how entities, attributes, metrics, and dimensions relate to each other, all anchored to the underlying physical schema.
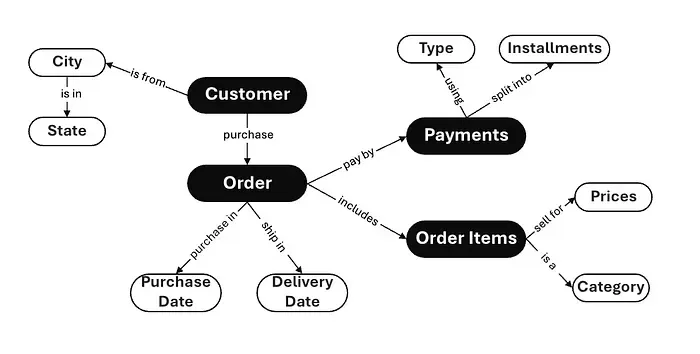
Key Aspects of MDL:
Define Entities and Attributes:
Instead of scattering relationships across multiple queries or dashboards, MDL lets you define business concepts as entities (like “Customers” or “Products”) and their properties as attributes. These can be mapped to one or more physical database tables.
Express Metrics and Dimensions:
MDL centralizes the definition of metrics (like “Total Revenue” or “Average Order Value”) and their related dimensions (time periods, regions, categories). This ensures canonical definitions and consistency across all queries.
Encapsulate Logic:
Transformations, filters, and derived metrics live in one place. Instead of rewriting logic in each SQL query, you record it once in MDL. This reduces the risk of hallucinations because the model refers to a single source of truth. Rather than guessing relationships or metrics, the model uses the context layer defined by MDL to produce grounded queries.
By leveraging MDL, Wren AI doesn’t just rely on raw schema inputs; it taps into a semantic model that aligns the LLM’s outputs with your business reality. Entities, attributes, metrics, and relationships are defined once, ensuring that even complex queries have a stable reference point. This makes hallucinations less likely because the model can’t arbitrarily invent entities or metrics that don’t exist in the MDL-based context layer.
How Wren AI Approaches the Hallucination Problem
Wren AI employs a multifaceted strategy to reduce hallucinations:
Schema-First Philosophy:
Wren AI ensures the model always operates with explicit schema context. The schema is provided as part of the prompt, setting clear boundaries on what the model can reference.
Contextual Query Routing:
If a user request doesn’t align with the known schema or context layer, Wren AI can gracefully refuse or redirect the query. This prevents the model from attempting to invent columns or tables it can’t find.
Step-by-Step Reasoning and Transparency:
Wren AI encourages the model to break down its reasoning before finalizing a query. This chain-of-thought approach helps catch errors early. The system can surface this reasoning to users who want to understand how the query was formed.
Built-In Validation and Dry-Runs:
After generating a query, Wren AI performs a validation step. It attempts a dry-run against your database. If the query fails, due to a missing column or a syntax error, the system uses that feedback to adjust and regenerate the SQL. This immediate loop of trial and correction drastically reduces hallucinations.
Semantic Layer with MDL:
With MDL, Wren AI’s context layer ensures that the model doesn’t just know what tables and columns exist, it also knows the business meaning behind them. By drawing on a carefully curated semantic model, the system is less likely to produce irrelevant or incorrect fields. The model looks up the defined metrics and dimensions in MDL instead of inventing them, reducing the cognitive load on the LLM and minimizing guesswork.
In essence, Wren AI’s approach involves combining robust schema grounding, semantic modeling, reasoning transparency, and iterative validation. Each element targets a different root cause of hallucinations, making the entire pipeline more reliable.
Try it yourself with Wren AI!
Hallucinations in text-to-SQL are not an inevitability. With the right strategies (schema grounding, semantic modeling, retrieval augmentation, validation steps, transparency, and iterative improvement) it’s possible to significantly reduce their occurrence and impact. The result is a system that everyone, from analysts to executives, can rely on for trustworthy insights.
Wren AI embodies these principles. It leverages a schema-first approach, dry-run validations, and the powerful Metadata Definition Language (MDL) to ensure that the underlying context layer is not only well-defined but also fully integrated into the query generation process. By doing so, Wren AI drastically lowers the chances of hallucinations and fosters a more confident, data-driven culture.
Want to learn more? Check our related articles 👇
- Why the Semantic Layer is Essential for Reliable Text-to-SQL and How Wren AI Brings it to Life
- The new wave of Composable Data Systems and the Interface to LLM agents
- How we design our semantic engine for LLMs? The backbone of the context layer for LLM architecture.
Ready to take the next step?
Check out our website at https://getwren.ai/ to learn how Wren AI can transform your data access strategy.
We also offer an open-source version on GitHub: https://github.com/Canner/WrenAI. Explore the code, try it out, and see firsthand how a semantic-driven, grounded approach to text-to-SQL can make a real difference in your organization.
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free TrialRelated Posts
Beyond Text-to-SQL: Why Feedback Loops and Memory Layers Are the Future of GenBI
How Wren AI’s Innovative Approach to Question-SQL Pairs and Contextual Instructions Delivers 10x More Accurate Generative Business Intelligence
Jan 03, 2025How Uber is Saving 140,000 Hours Each Month Using Text-to-SQL, And How You Can Harness the Same Power
Discover how Uber’s Text-to-SQL technology streamlines data queries and learn how to apply this efficiency to your operations.
Aug 20, 2025How Wren AI Agent Supercharges the Future of Marketing Measurement Platforms
Marketing Measurement Platforms (MMPs) are pivotal for performance marketers seeking to unify data and fuel more innovative campaign strategies.

Keep reading
 Insight
InsightBeyond Text-to-SQL: Why Feedback Loops and Memory Layers Are the Future of GenBI
How Wren AI’s Innovative Approach to Question-SQL Pairs and Contextual Instructions Delivers 10x More Accurate Generative Business Intelligence
 Insight
InsightHow Uber is Saving 140,000 Hours Each Month Using Text-to-SQL, And How You Can Harness the Same Power
Discover how Uber’s Text-to-SQL technology streamlines data queries and learn how to apply this efficiency to your operations.
 Insight
InsightHow Wren AI Agent Supercharges the Future of Marketing Measurement Platforms
Marketing Measurement Platforms (MMPs) are pivotal for performance marketers seeking to unify data and fuel more innovative campaign strategies.