How do we rewrite Wren AI LLM Service to support 1500+ concurrent users online?
How Wren AI LLM Service leverages Haystack and Hamilton as performant Generative AI infrastructure

Howard Chi
Updated: Dec 18, 2025
Published: Aug 20, 2024
Note: this post predates Agentic GenBI. The engineering deep-dive below still holds, but it frames Wren AI as a text-to-SQL tool. Today Wren AI is an agent that reasons over a governed context layer, with skills and memory, for humans and agents alike. Read "Introducing Agentic GenBI" to see how the product works now.
In generative AI applications, often the performance bottleneck is due to the long latency of LLM execution, thus, it’s crucial to combat this issue. In this article, I will share with you how we leverage Haystack and Hamilton to make AI pipelines fully asynchronous and can support 1500+ concurrent users!
What is Wren AI LLM Service responsible for?
Wren AI is a text-to-SQL solution for data teams to get results and insights faster by asking business questions without writing SQL. It’s open-source! Wren AI LLM Service is responsible for LLM-related tasks like converting natural language questions into SQL queries and providing step-by-step SQL breakdowns.
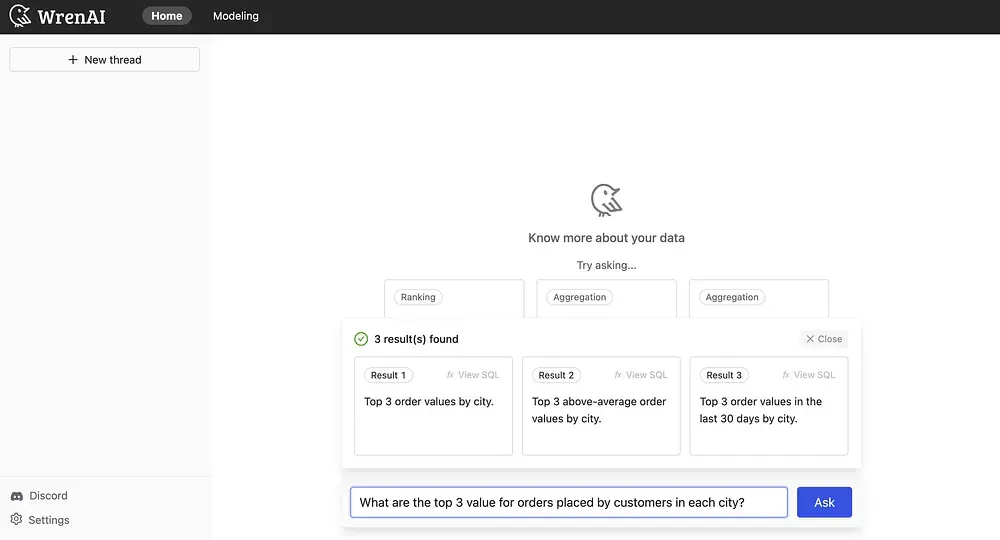
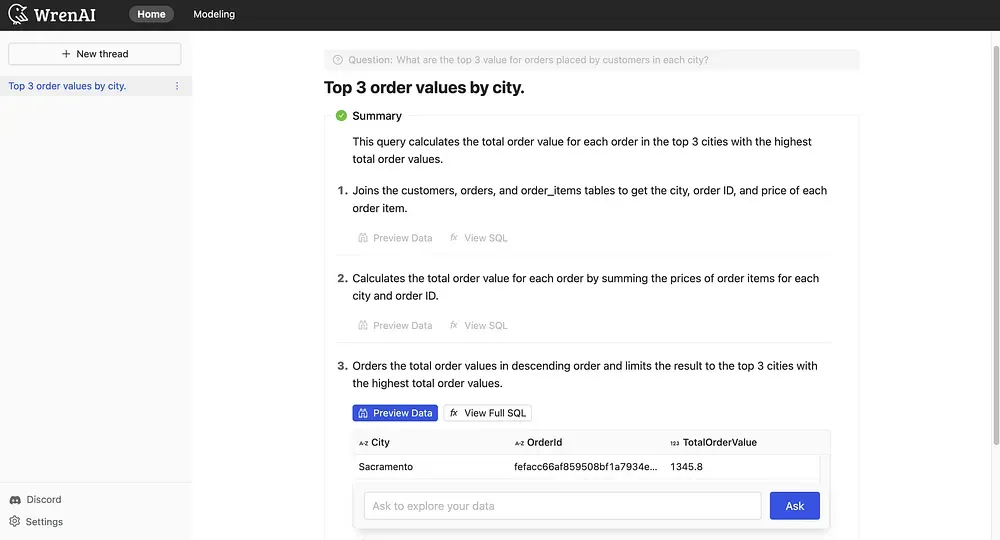
Notes: The tasks described above are the main tasks for Wren AI LLM Service as of now, and there are several other potential new functionalities in our backlog or progress, such as text-to-chart, recommend follow-up questions, recommend new questions after the user is on-boarded, feedback loop, clarification, llm system evaluation framework, etc. Welcome to discuss with us and share your thoughts, on our Discord Server!
The Evolution of Wren AI LLM Service Architecture
Wren AI LLM Service 1.0: No LLM Framework
The first version of Wren AI LLM Service did not utilize any large language model (LLM) frameworks. Instead, it relied on:
- LiteLLM for connecting to LLMs
- Chroma as the vector database
As a result, the first version is a naive RAG for the text-to-SQL task.
The Challenge
After the first version was done, we understood that there are some challenges if we would like to support more complex AI pipelines:
- There should be an easier way to support AI pipelines as DAGs(directed acyclic graphs).
- We may need to support other LLMs and vector databases in the future.
Wren AI LLM Service 2.0: Haystack
After one week’s survey, we decided to choose Haystack as our infrastructure to build generative AI applications. We started to use it during its 2.0 beta version. There are several reasons why we chose Haystack, listed as follows:
- Simple APIs, intuitive design, great community support, and good code readability
- Extensive pre-built LLM and Document Store integrations
- Easy creation of custom components
- The concept of pipeline as the core design philosophy
As a result, we can easily develop more complex AI pipelines and integrate other LLMs and Document Stores right away.
The Challenge
You may think Haystack is a perfect choice for building generative AI applications; unfortunately, there is no perfect software in the world. There is one challenge for our use case: we need to consider the performance of the application in terms of user’s requests per second(a.k.a throughput) and time spent per user’s request(a.k.a latency).
Since Haystack doesn’t have built-in async support, the pipeline computation is synchronous by default(The bottleneck of the generative AI applications is usually rooted in the long latency of LLM execution). So, we need to make our AI pipelines async to combat the issue. (This issue is one of the popular raised topics, and there is a slide shared by the Haystack team introducing several proposals to combat the issue)
Wren AI LLM Service 3.0: Haystack + Hamilton
We thought a candidate solution should have at least these criteria:
- It can easily provide an asynchronous computation environment for our AI pipelines.
- It can be easily integrated with Haystack
We found a library called Hamilton. Hamilton is a lightweight Python library that can help us separate pipeline computation logic from the computation runtime environment.
Quoted from Hamilton’s GitHub page:
Hamilton is a lightweight Python library for directed acyclic graphs (DAGs) of data transformations. Your DAG is portable; it runs anywhere Python runs, whether it’s a script, notebook, Airflow pipeline, FastAPI server, etc. Your DAG is expressive; Hamilton has extensive features to define and modify the execution of a DAG (e.g., data validation, experiment tracking, remote execution).
To create a DAG, write regular Python functions that specify their dependencies with their parameters. As shown below, it results in readable code that can always be visualized. Hamilton loads that definition and automatically builds the DAG for you!
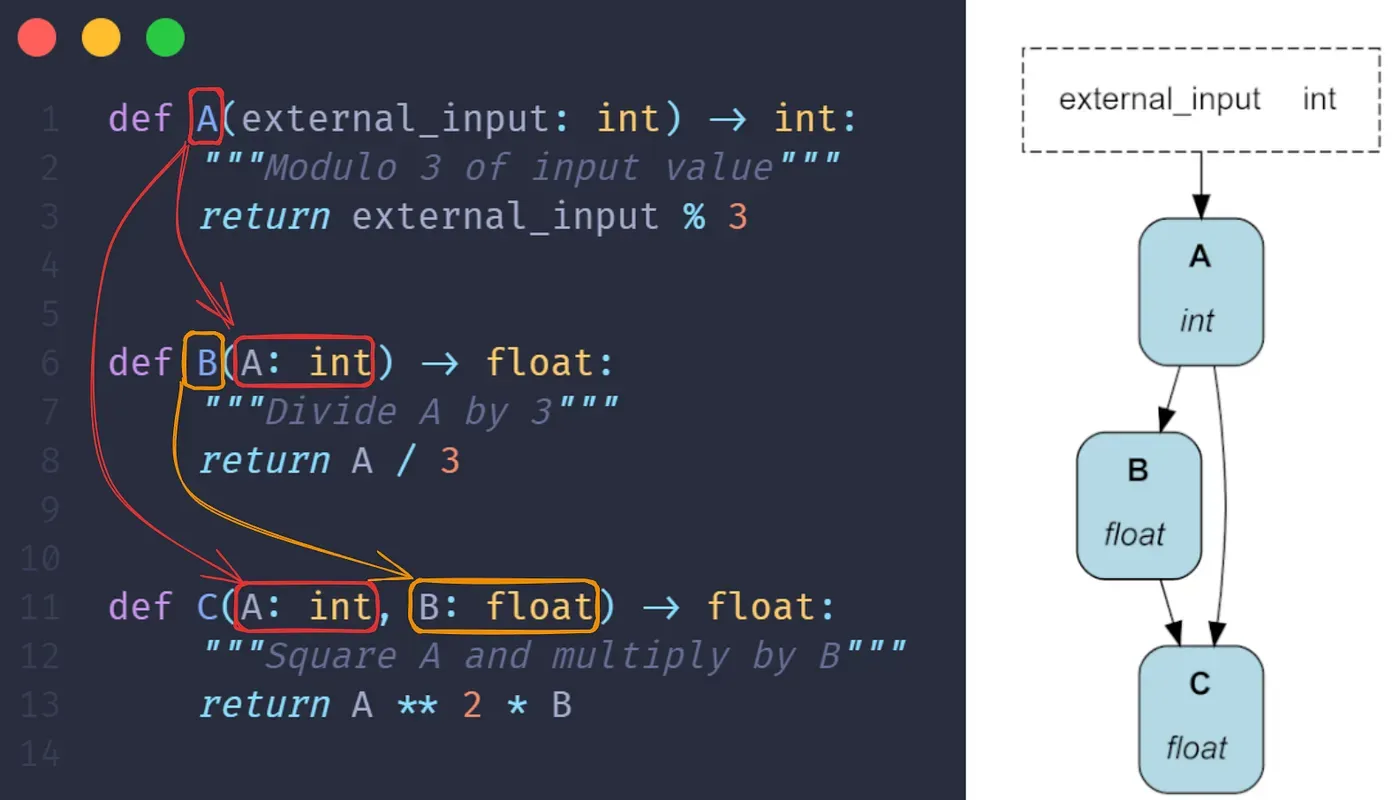
Image from Hamilton’s GitHub page
Architecture Rewrite Results
You can see the differences between using Haystack alone and Haystack integrated with Hamilton with code snippets provided below:
Code Snippets Before rewriting the AI pipeline using Hamilton
- We compose the pipeline in the
__init__method of theGenerationclass with pipeline’s built-inadd_componentandconnectmethods. - We define a
runmethod to invoke the pipeline execution.
Code snippets after rewriting the AI pipeline using Hamilton
- We still define Haystack components in the
__init__method of theGenerationclass; however, we declare how the components should stick together by describing the connections between components using functions. - We still define a
runmethod for invoking pipeline execution, but under the hood, it’s Hamilton’sAsyncDriver.
Performance Testing Results
Now, I am going to show you a series of performance testing results to prove that our architecture rewrite is successful and why we say that our LLM service can handle 1500+ concurrent users?(Wren AI LLM Service is a FastAPI server run with one uvicorn worker)
First of all, the performance improvement is substantial:
- The number of requests improved from 16 to 716, improved over 44x
- Average requests per second(a.k.a throughput) improved from 0.8 to 34.3, improved over 42x
- Average response time(a.k.a latency) improved from 7857.19ms to 1679.51ms, improved over 4.5x
Performance statistics before rewriting the AI pipeline using Hamilton
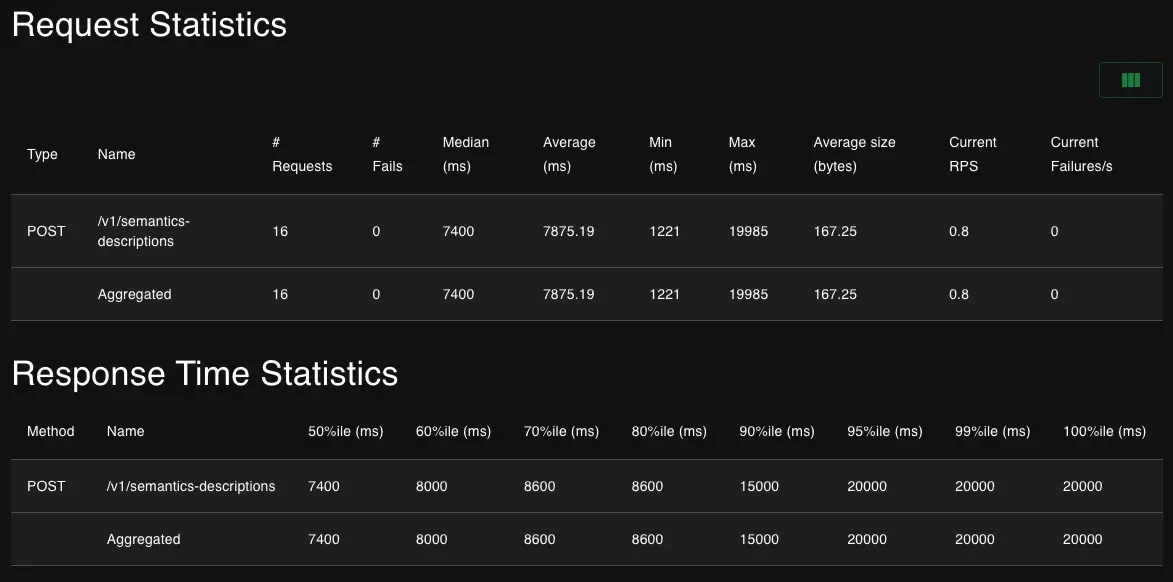
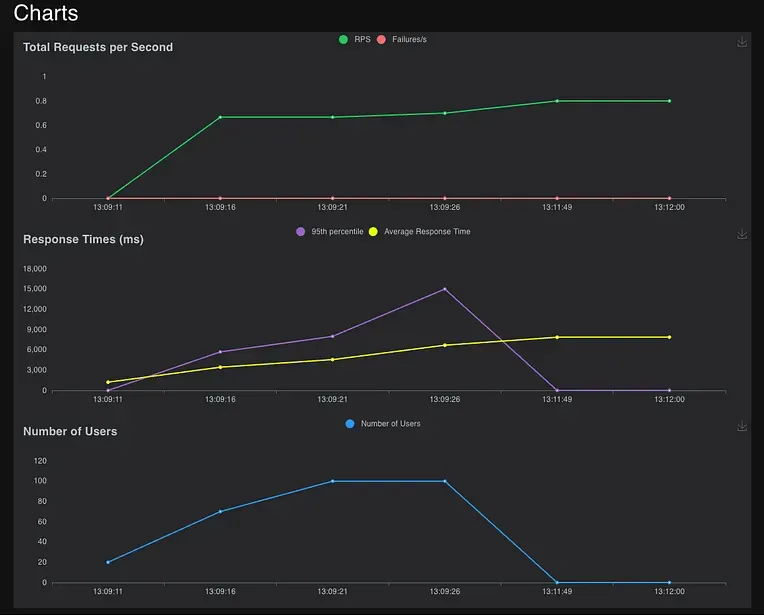
Performance statistics before rewriting the AI pipeline using Hamilton
Performance statistics after rewriting the AI pipeline using Hamilton
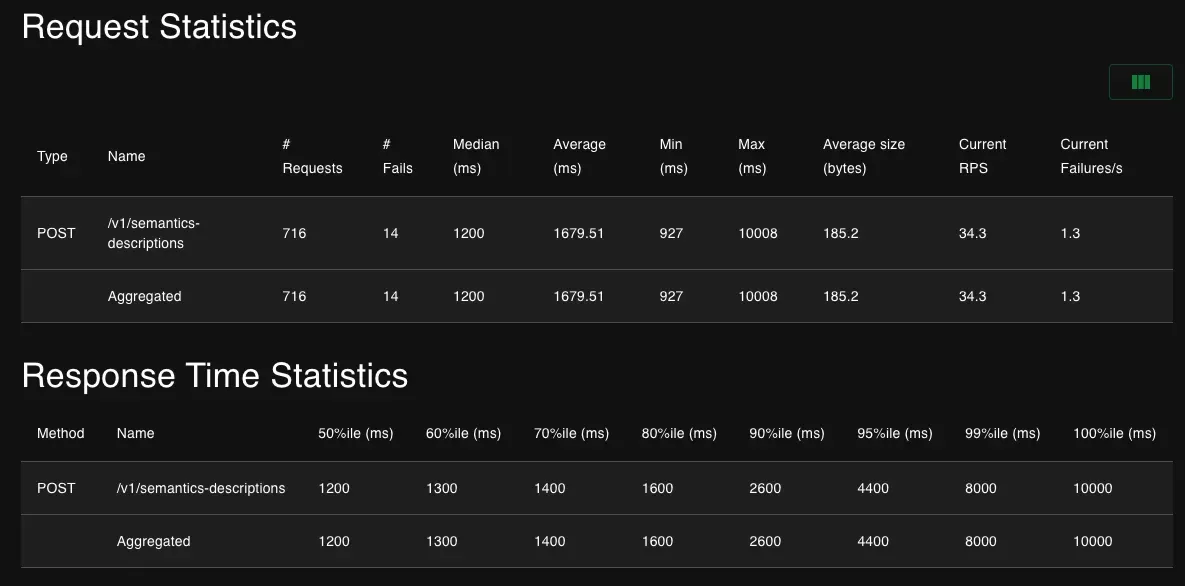
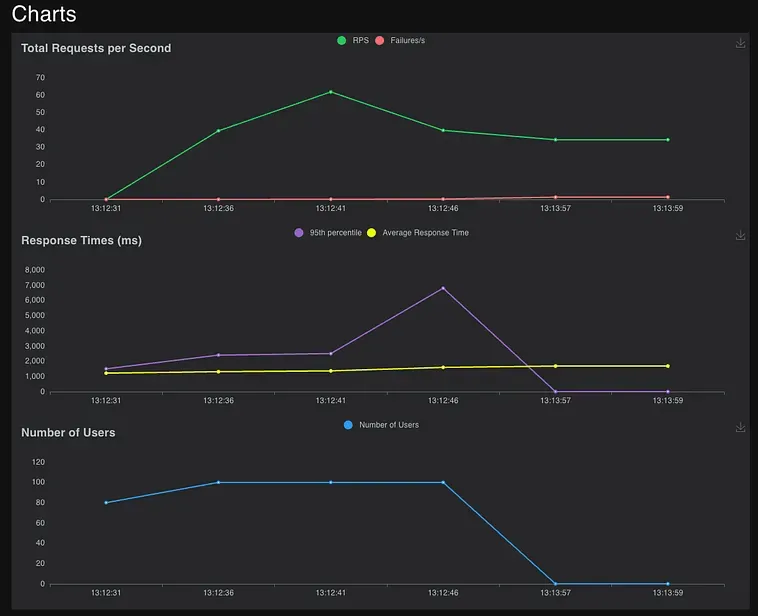
Performance statistics after rewriting the AI pipeline using Hamilton
Also, to make sure our AI pipeline is indeed capable of doing asynchronous computation, I’ve built a “simulated API” that mimics AI pipeline behavior to compare with the real AI pipeline API.
You can easily see the similar performance statistics here:
Number of requests finished
- Simulated API: 30
- Real AI pipeline API: 31
Average requests per second(a.k.a throughput)
- Simulated API: 1.6
- Real AI pipeline API: 1.6
Average response time(a.k.a latency)
- Simulated API: 2.53ms
- Real AI pipeline API: 5.35ms
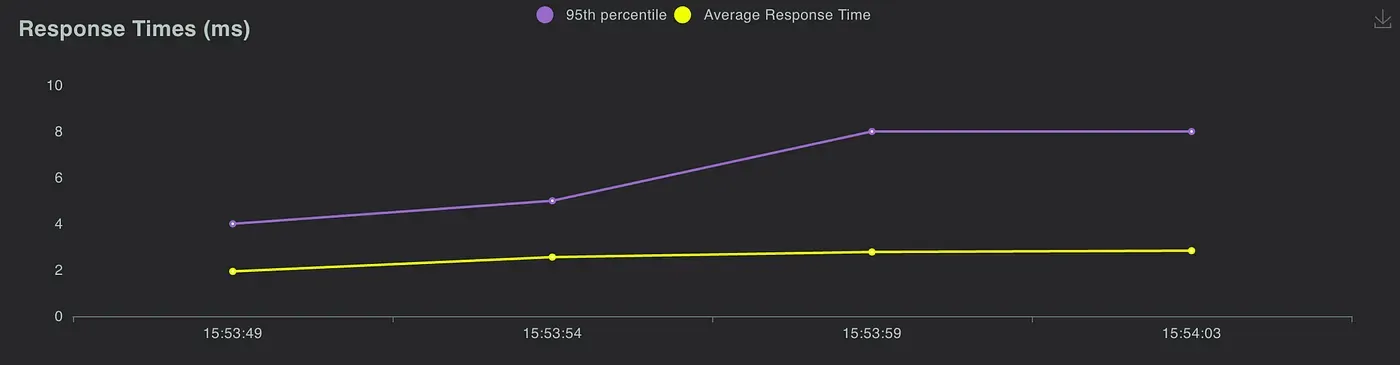
Simulated API version

Requests statistics
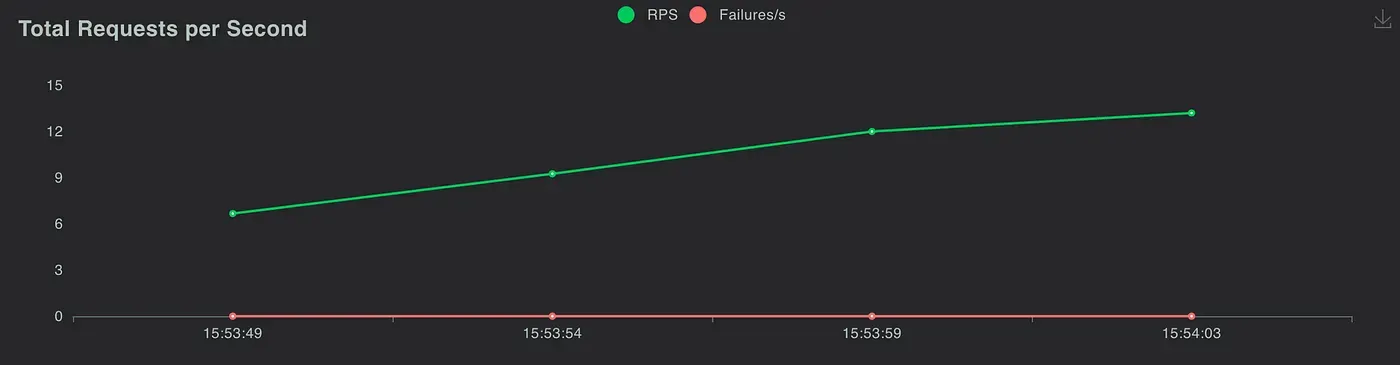
Total requests per second
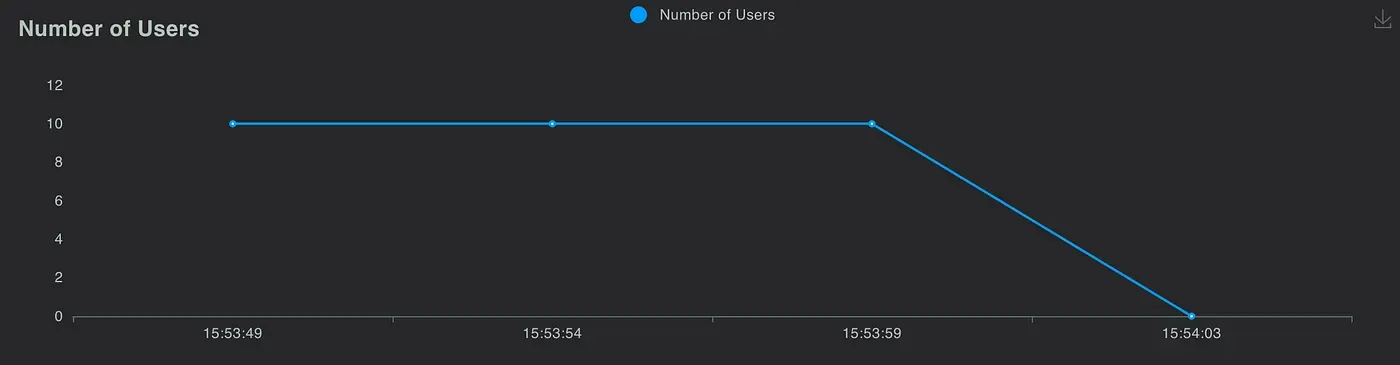
Number of users
Real AI pipeline API version

Requests statistics
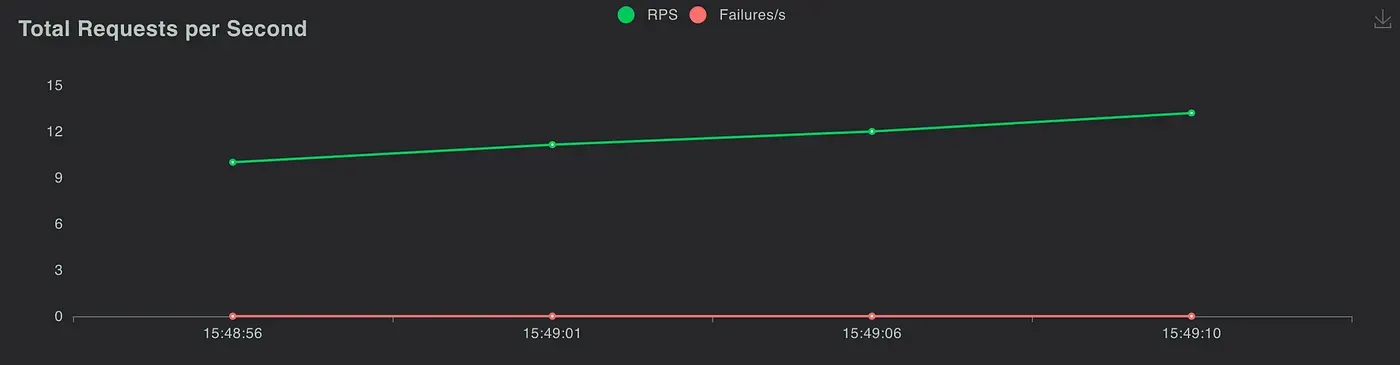
Total requests per second
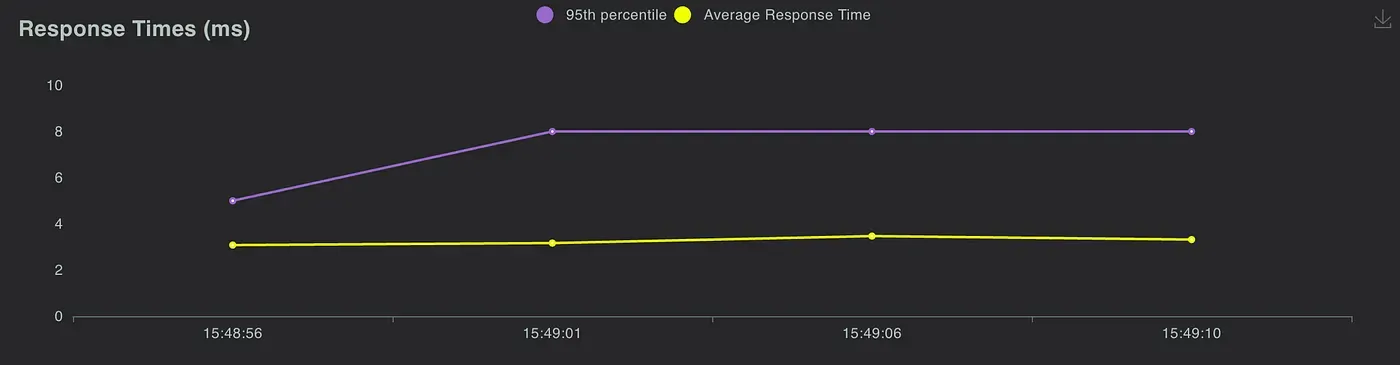
Response time
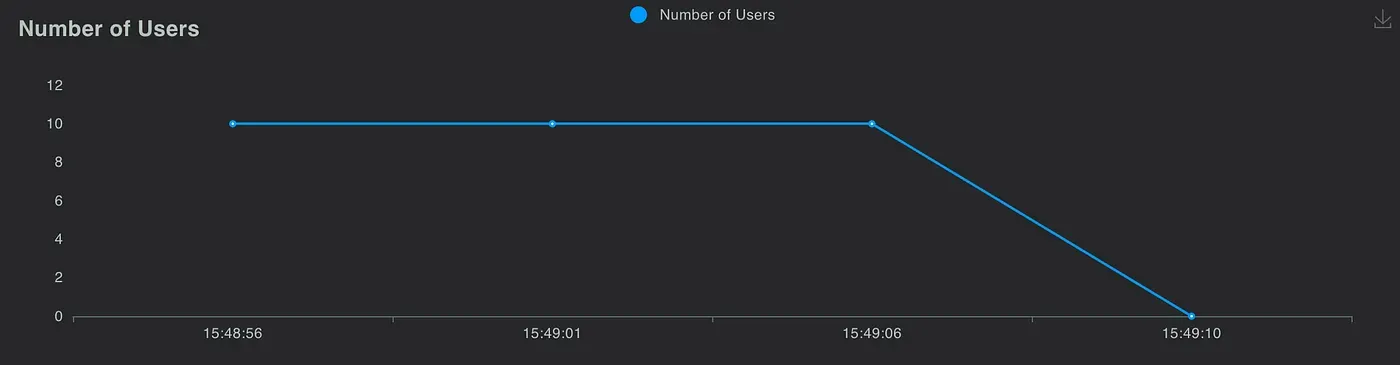
Number of users
You can see that they both have similar performance statistics, so we believe implementing the third version architecture is successful!
Finally, I will share with you how we can infer that our LLM service can handle 1500+ concurrent users. Since I’ve shown you that the performance statistics between the simulated API and the real API are similar. Thus I hypothesize that if we can prove the simulated API version can handle 1500+ concurrent users, then I can infer that the real API version can also achieve the same results. (I assume the LLM can handle 1500+ concurrent users here)
You can see that the performance statistics are quite healthy!
- Number of requests finished: 16358
- Average requests per second(a.k.a throughput): 267.5
- Average response time(a.k.a latency): 92.52ms

1_Gxrive1u2vh2U8PvJeOEkw.webp
Request statistics
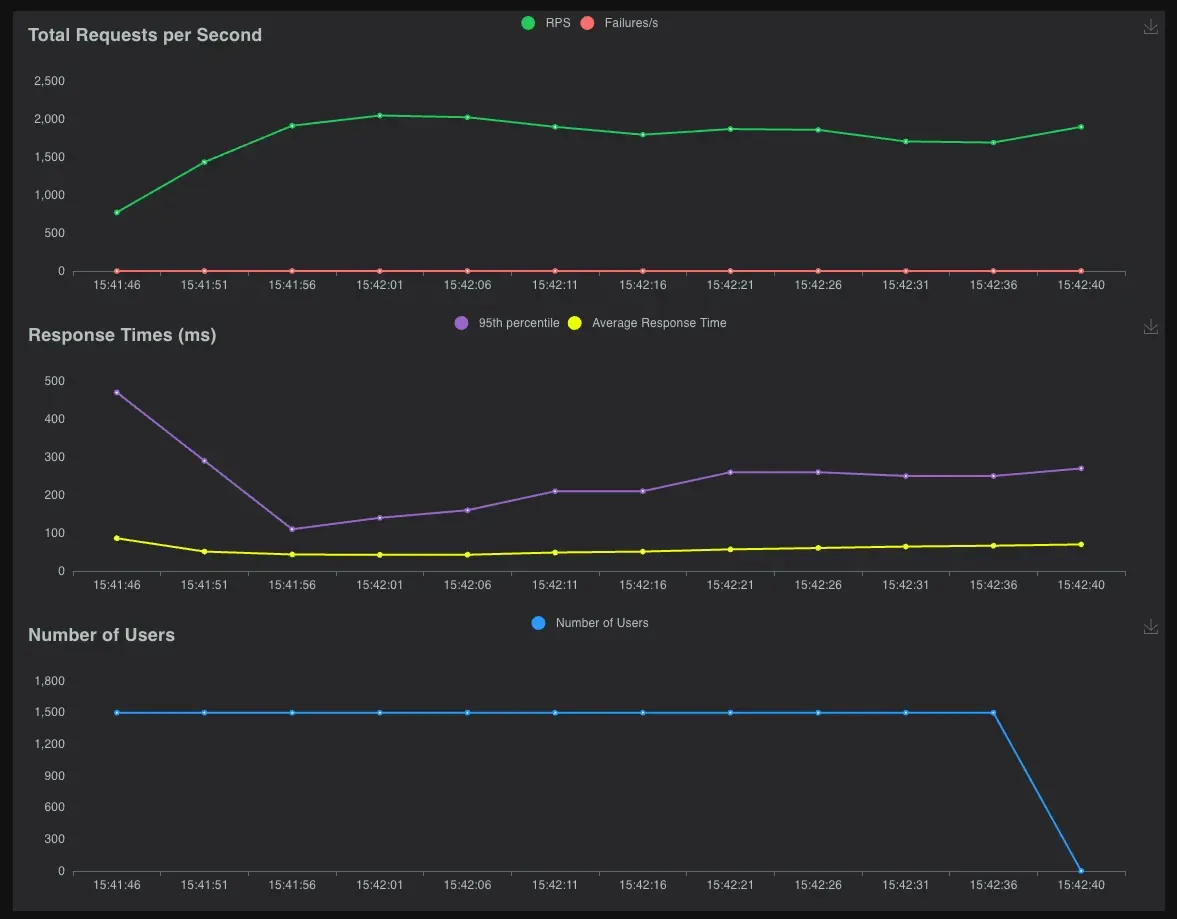
Performance chart
Notes: the tests were all done on my MacBook Pro(14-inch, 2023 with Apple M2 Pro, 16GB Memory)
Final Remarks
I hope this article can help you understand some issues you may encounter while building generative AI applications. I also hope the tools I mentioned in this article can help you solve issues more easily! These are all great open-source software tools we can leverage and learn from!
Feel free to leave a comment in this post if you have any thoughts you would like to discuss on the topic. Thanks!
Thanks to Howard Chi and William Chang, who reviewed the post and provided feedback!
👉 GitHub: https://github.com/Canner/WrenAI
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free TrialRelated Posts
Beyond Dashboards How Conversational AI is Revolutionizing Structured Finance Analytics
How Wren AI transforms complex financial data into instant, actionable insights through natural language, no technical expertise required
Mar 31, 2025Fueling the Next Wave of AI Agents Building the Foundation for Future MCP Clients and Enterprise Data Access
How Wren Engine Powers the Semantic Layer for AI-Driven Workflows, Unlocking Context-Aware Intelligence Across the MCP Ecosystem
Jan 03, 2025How Uber is Saving 140,000 Hours Each Month Using Text-to-SQL, And How You Can Harness the Same Power
Discover how Uber’s Text-to-SQL technology streamlines data queries and learn how to apply this efficiency to your operations.

Keep reading
 Insight
InsightBeyond Dashboards How Conversational AI is Revolutionizing Structured Finance Analytics
How Wren AI transforms complex financial data into instant, actionable insights through natural language, no technical expertise required
 Product
ProductFueling the Next Wave of AI Agents Building the Foundation for Future MCP Clients and Enterprise Data Access
How Wren Engine Powers the Semantic Layer for AI-Driven Workflows, Unlocking Context-Aware Intelligence Across the MCP Ecosystem
 Insight
InsightHow Uber is Saving 140,000 Hours Each Month Using Text-to-SQL, And How You Can Harness the Same Power
Discover how Uber’s Text-to-SQL technology streamlines data queries and learn how to apply this efficiency to your operations.