The new wave of Composable Data Systems and the Interface to LLM agents
The new interface to bridge AI agents and the data system. How can we manage and design to meet the future demands of multi-AI agents?

Howard Chi
Updated: Dec 18, 2025
Published: Aug 20, 2024

Note: this post predates Agentic GenBI. The analysis below still holds, but it frames Wren AI as a text-to-SQL tool. Today Wren AI is an agent that reasons over a governed context layer, with skills and memory, for humans and agents alike. Read "Introducing Agentic GenBI" to see how the product works now.
In traditional databases and data warehouses, the architecture designs are optimized for each system's storage, computing, SQL, and API. Most databases and data warehouses have their own unique system designs, and the design comes all together as a monolithic data system. This has worked very well over the decades. Companies and users can easily install the system and start storing and querying the data.
However, in recent years, we have seen a shift in the database system; we see commercial major cloud data warehouse vendors moving towards supporting open standards in storage such as Snowflake started supporting Apache Iceberg and Apache Parquet, Databricks open-sourcing Delta Lake format, BigQuery supporting Apache Iceberg format, AWS Redshift supporting Apache Iceberg; and in data output format, Snowflake, BigQuery, Databricks, Dremio start supporting Arrow format, we see this trend is going to become mainstream in following years.
The movement does not stop at storage and output format but further into decomposed execution engines, such as Meta's open-source Velox, a composable execution engine that could replace Presto workers and the Spark engine. DuckDB is surging incredibly fast as a new type of in-process analytical database. Apache DataFusion is another example of an extensible query engine that uses Apache Arrow as the in-memory format.
Other projects such as Ibis standardizing Dataframe library and Substrait for standardizing Intermediate Representation(IR) between computing engines. One of the major companies behind this movement is Voltron Data, which is pushing innovation forward to the new frontier of data systems.
Even though building data systems is very expensive, database vendors need to raise hundreds of millions of dollars to build, and today we have hundreds of database choices served in different niches.
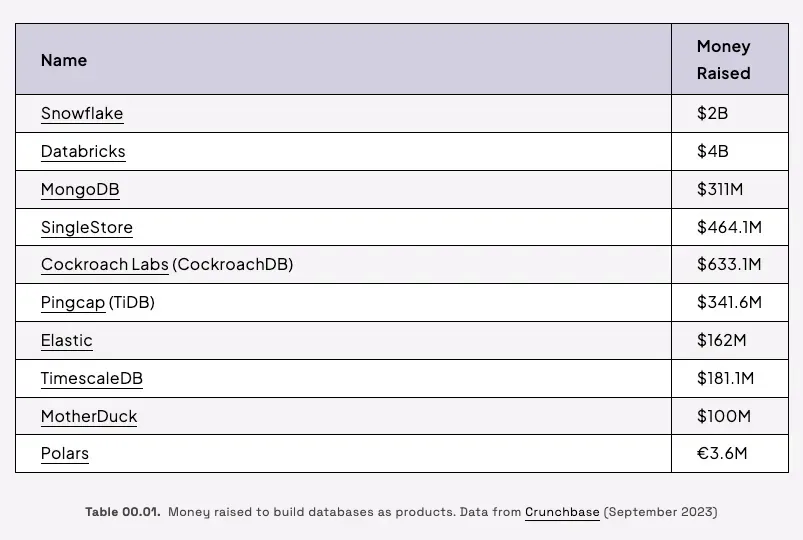
Image from Voltron Data Codex
In this blog post, I will share why the composable data system concept became the new frontier of building data systems, the benefits of this new trend, and how it will enable and power the new generation of analytics applications.
Lastly, we will share about the Large Language Model(LLM) to SQL has become a new trend in data vendors, such as the recent announcement of Snowflake launching Snowflake Copilot and Databricks launching Databricks AI/BI Genie. More vendors will join forces in the following years to enable LLM capability in their data infrastructure. In the context of composable data systems, how can we modulize the LLM interface to provide a standard layer for LLM Agents that fits into the composable data stack ecosystem in the LLM era.
Why Now?
Language silos in storage, data structures, and compute engines have huge overhead
Wes McKinney’s talk about “Data Science without Borders” clearly articulates this challenge; we have been experiencing “Language silos” for years, which means we had to reimplement the same logic and code between different programming languages, such as Python, R, and JVM, Julia, etc. The language silos make common patterns, such as storage (data access), data structure (in-memory formats), general compute engine(s), and advanced analytics, can’t be reused, and is highly dependent on the front-end (Languages).
The rise of GPUs and specialized hardware
Because of the AI arms race, even before the start of the current AI trend, enterprises need faster, more scalable, and cost-effective machine learning infrastructure.
The processor, the engine that drives the computer industry, known as the central processing unit (CPU), has seen its performance topped out. Yet, the amount of computation we need to perform continues to double very quickly—exponentially. This is even more substantial in the AI/ ML workload, in which data is consumed on a much larger scale.
![NVIDIA CEO Jensen Huang Keynote at COMPUTEX 2024]
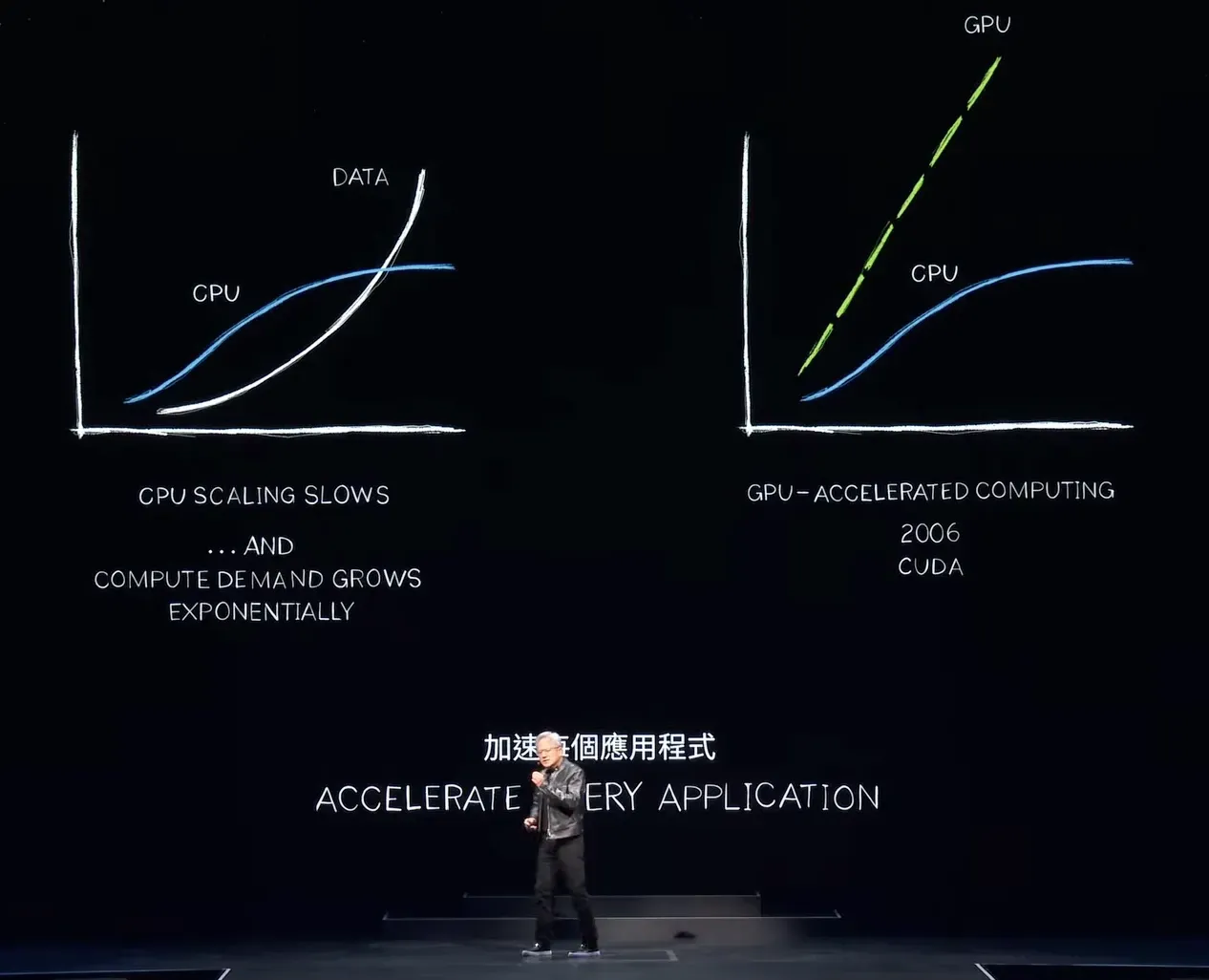
NVIDIA CEO Jensen Huang Keynote at COMPUTEX 2024
Quote from a recent talk from NVIDIA CEO Jensen Huang Keynote at the Computex 2024
If the processing requirement and the data we need to process continue to scale exponentially while performance does not, we will experience computation inflation. *In fact, we are seeing this right now. The amount of data center power used worldwide is growing substantially, and the cost of computing is increasing. We are experiencing computation inflation. This cannot continue; the data will continue to increase exponentially, but CPU performance scaling will never return.*If the processing requirement and the data we need to process continue to scale exponentially while performance does not, we will experience computation inflation. In fact, we are seeing this right now. The amount of data center power used worldwide is growing substantially, and the cost of computing is increasing. We are experiencing computation inflation. This cannot continue; the data will continue to increase exponentially, but CPU performance scaling will never return.

NVIDIA CEO Jensen Huang Keynote at COMPUTEX 2024
Through parallel processing, adding GPUs to the CPUs improves the new chip architecture hugely. Specialized hardware, such as GPUs, TPUs, and ASICs, can take tasks that currently require a great deal of time and accelerate them to completion incredibly fast. This will become the upcoming major evolution in the data processing and analytics sector.
The software needs to be completely rewritten in order to re-architect and re-implement the algorithms that were originally designed for a CPU. This will enable the tasks to be offloaded, accelerated, and run in parallel, resulting in incredibly fast processing.
It makes more sense to modularize the data stack so that we can easily reimplement and interchange logic between different chips instead of rewriting the monolithic database and data warehouses repeatedly.
The Concept, A Modular, Composable Data Stack
Two of the most important traits of achieving a composable data ecosystem are reusability and interoperability; this means the modules/ libraries need to compact into components and have a standard agreed upon an open community to allow downstream and upstream dependencies to work with each other, this needs to complement two forces open-source, and standardization.
Quote from “The Composable Data Management System Manifesto”
Considering the recent popularity of open-source projects aimed at standardizing different aspects of the data stack, we advocate for a paradigm shift in how data management systems are designed. We believe that by decomposing these into a modular stack of reusable components, development can be streamlined while creating a more consistent experience for users.
Structure of a composable data system
In the Voltron Data Composable Codex, they outlined the three main layers; this is not a new architectural design of a data system; it is usually implemented internally into the traditional data systems we are all using today. The difference is that we have to now decompose into logical components with standards. The three main layers are:
User Interface
The user interface is usually where users initiate data operations, which typically means SQL, APIs, and languages such as Python, R, Java, etc.
Execution Engine
The engine is where operations are performed on the data, such as query optimization, executing logical, and physical plans, etc.
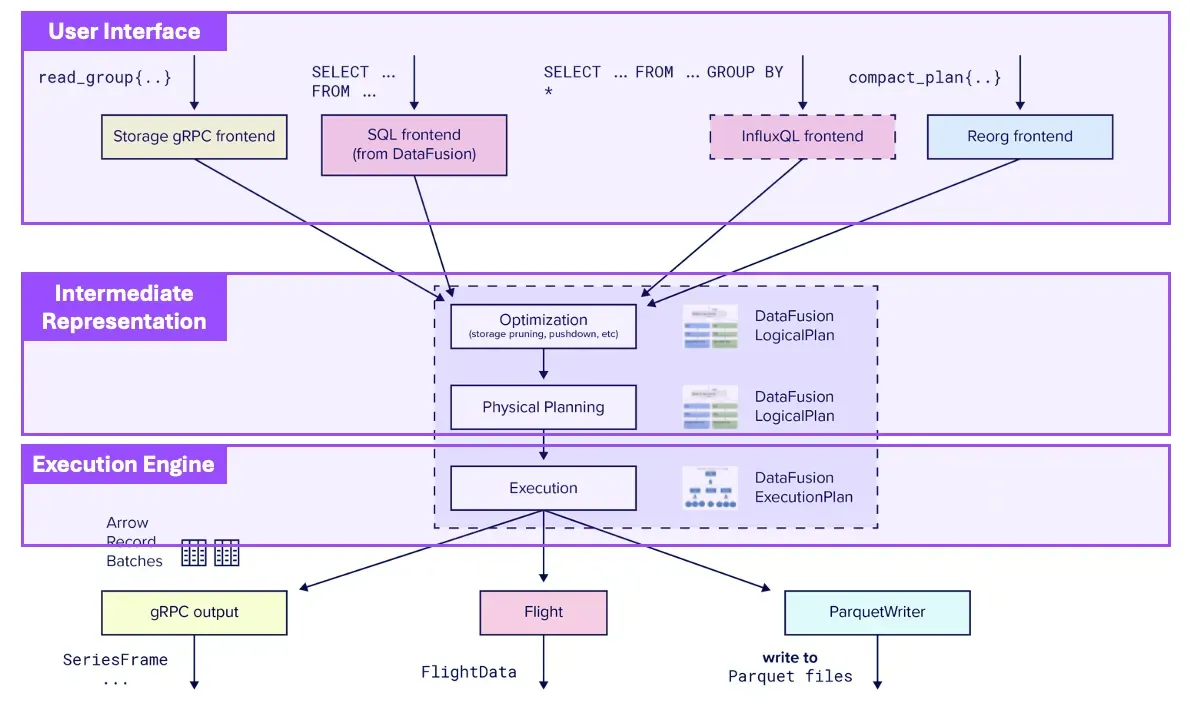
Image from Influx Data blog, Which illustrates the execution engine and user interface work together to generate the results a user wants
Data Storage
The Data Storage layer is where the data is stored and how it is stored.
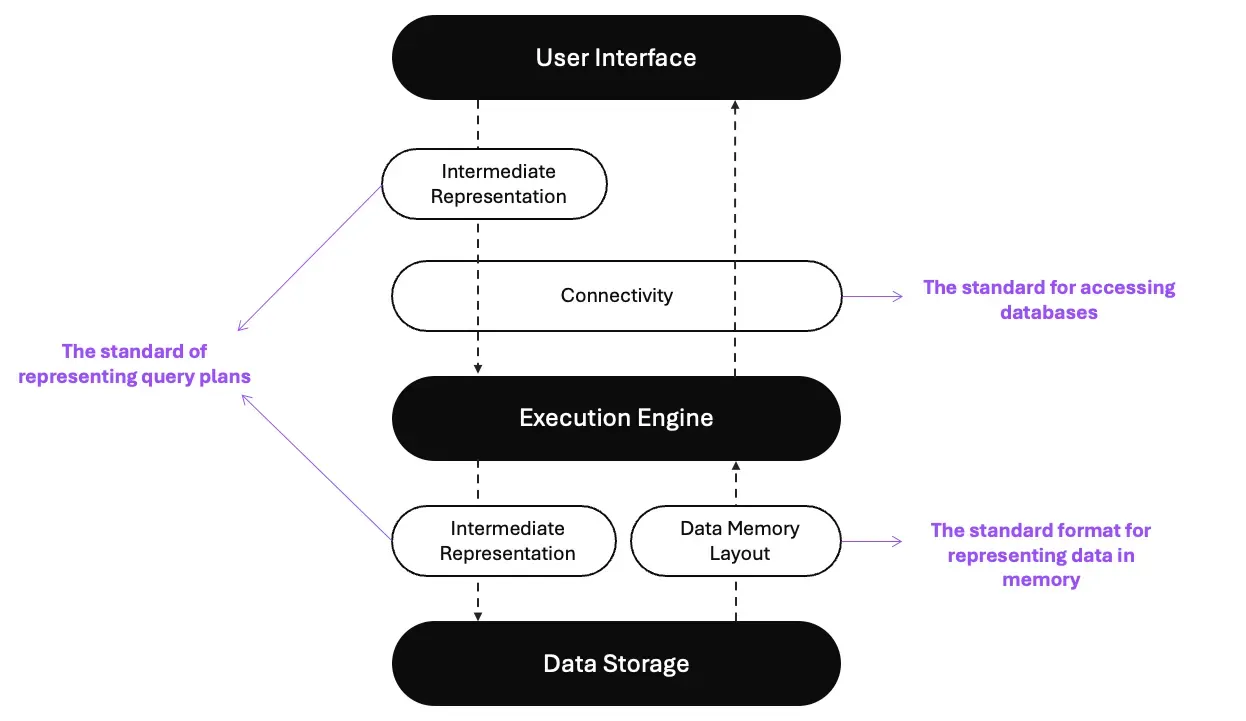
Structure of a composable data system
If you are interested in the details, please check out the article in Voltron Data, “The Composable Codex.”
Benefits of Composable Data System
The benefits of leveraging the Composable Data Stack to build your next data system are pretty straightforward here; I’m going to refer to what Voltron Data called “MICE.” It stands for Modular, Interoperable, Customizable, and Extensible.
Based on the composable data system, you can easily extend to new hardware and engines. It is highly customizable, and components can be easily connected and exchange information. It can work standalone or be replaced with new modules easily.
Namely, the composable data stack will make it easier to take full advantage of GPUs and other hardware as the computing landscape evolves.
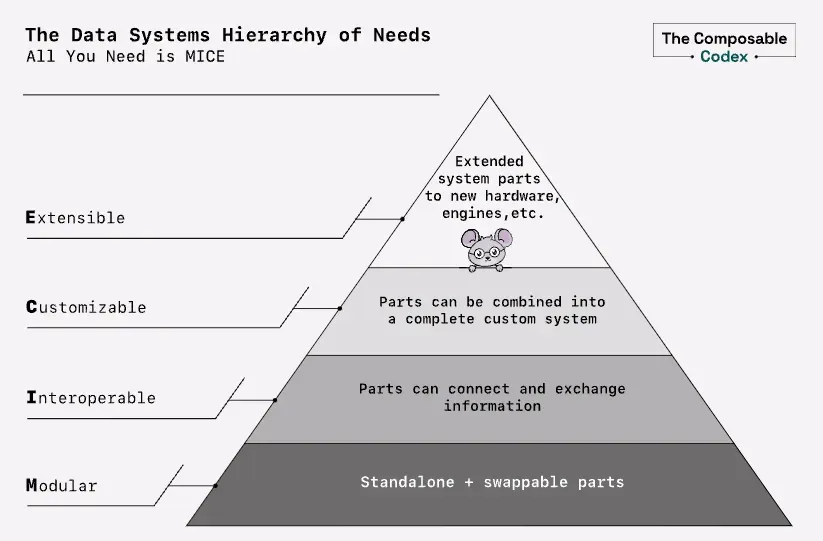
The data systems hierarchy of needs: All you need is MICE
You might think the composable data system looks great on paper, but how about in practice? Yes, let me show you the FDAP stack.
The FDAP Stack
One of the most recent notable case studies based on the composable data stack concept is, InfluxDB 3.0. In 2023 Oct, Influx Data coins a new term called “FDAP stack,” which proves that the composable data system didn’t sacrifice performance using the composable system; it resulted in more features and better performance than legacy designs.
Andrew Lamb’s recent talk at the Data Council outlined how InfluxDB transformed its infrastructure to, The FDAP Stack.
Andrew Lamb’s talk on Data Council
Back in 2020, Influx Data's CTO, Paul Dix, envisioned this new architecture that would change the OLAP database infrastructure. The key reason why the new FDAP stack makes much sense is that the volume of data transported between data processing and analytical systems has grown tremendously, thanks to the new trends in data science and AI/ ML workloads.
Traditionally, data is processed internally within OLAP and data warehousing systems, which is sufficient for most use cases. The primary use cases involve processing large volumes of data and aggregating it into metrics for business intelligence and reporting purposes. However, in machine learning and data science use cases, where transferring large amounts of data is necessary, the traditional ODBC did not perform well when moving data out of these systems.
The FDAP stack aims to use the open standards of the low-level architecture. This includes leveraging network protocol (Flight), query engine (DataFusion), memory format (Arrow), and storage format (Parquet). This is done to reduce the overhead of transporting data between systems and significantly minimize the engineering effort needed to create new analytic systems.
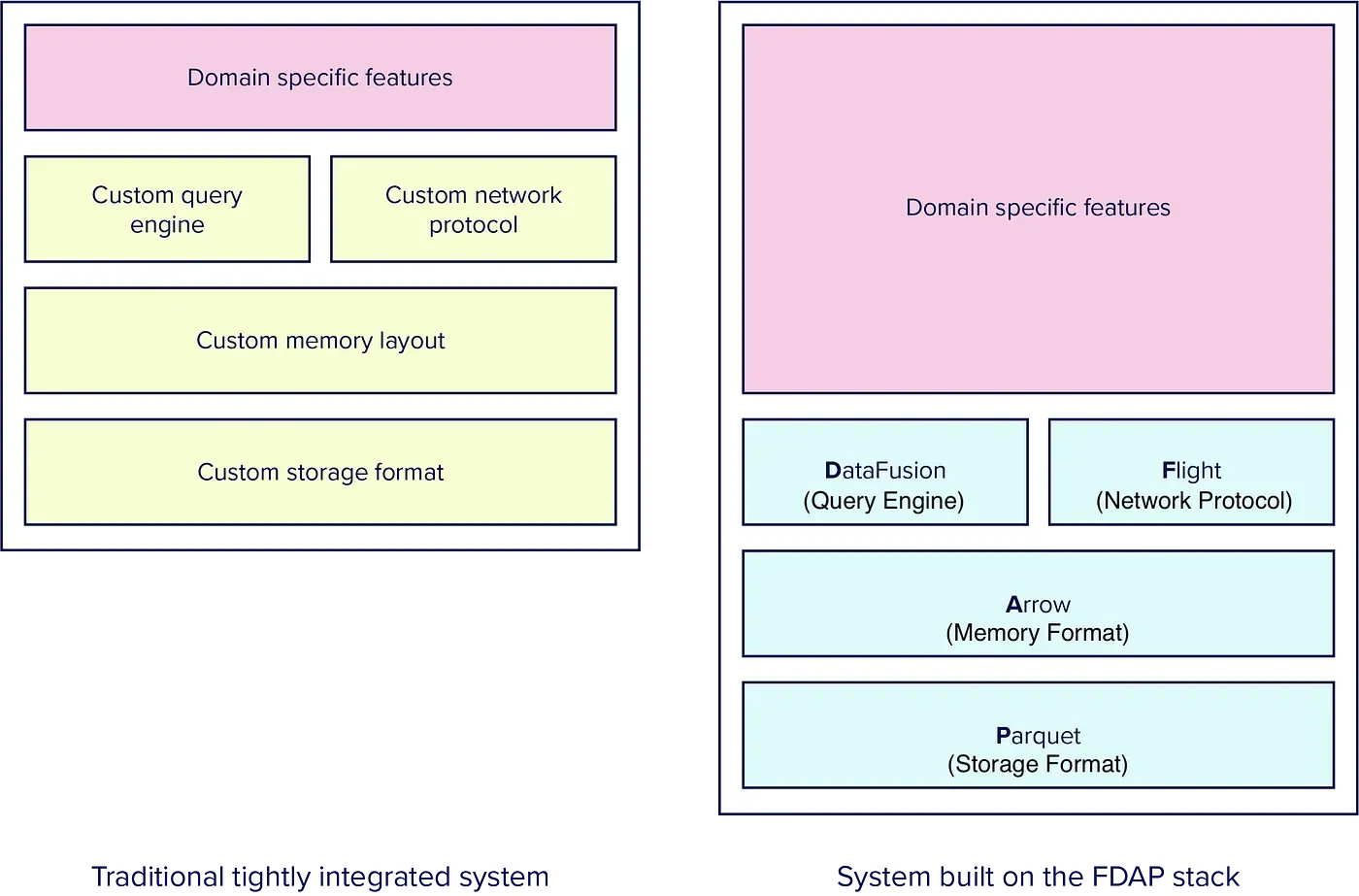
Image from Influx Data blog: “Flight, DataFusion, Arrow, and Parquet: Using the FDAP”
If you are interested in the details, please check out the article in Influx Data, “Flight, DataFusion, Arrow, and Parquet: Using the FDAP Architecture to build InfluxDB 3.0”.
The New Interface for LLM Agents
The recent rise of large language models(LLMs) has started a new wave of implementation to bring LLM capabilities into data infrastructure. Vendors like Snowflake and Databricks have started a new race. Recently, Snowflake launched Snowflake Copilot, and Databricks launched Databricks AI/BI Genie.
In early April this year, the Pinterest Engineering Team shared how they internally leveraged LLMs to retrieve data as the interface to users; they also shared an astonishing ROI on the solution provided to their users, quoted below.
In our real-world data (which importantly does not control for differences in tasks), we find a 35% improvement in task completion speed for writing SQL queries using AI assistance.
Introducing the LLM capability into data systems will be the next new interface for all data systems, making data accessible for more users in an organization.
What does the new component look like?
To achieve our goal, according to the three main layers defined by Voltron Data, we require an additional layer to support the LLMs. Between this layer and the user interface, we need an LLM intermediate representation (LIR) to connect the context between the data systems and the LLM Agents.
LLM Agents
The LLM Agents are systems that leverage LLMs to perform various tasks, such as chatbots, virtual assistants, and customer service automation.
LLM Intermediate Representation (LIR, Between LLM Agents and User Interface)
The LIR between the LLM agents and the User Interface(SQL, API) provides business context, including business terminologies, concepts, data relationships, calculations, aggregations, and access properties for users, to LLM agents and the execution engine.
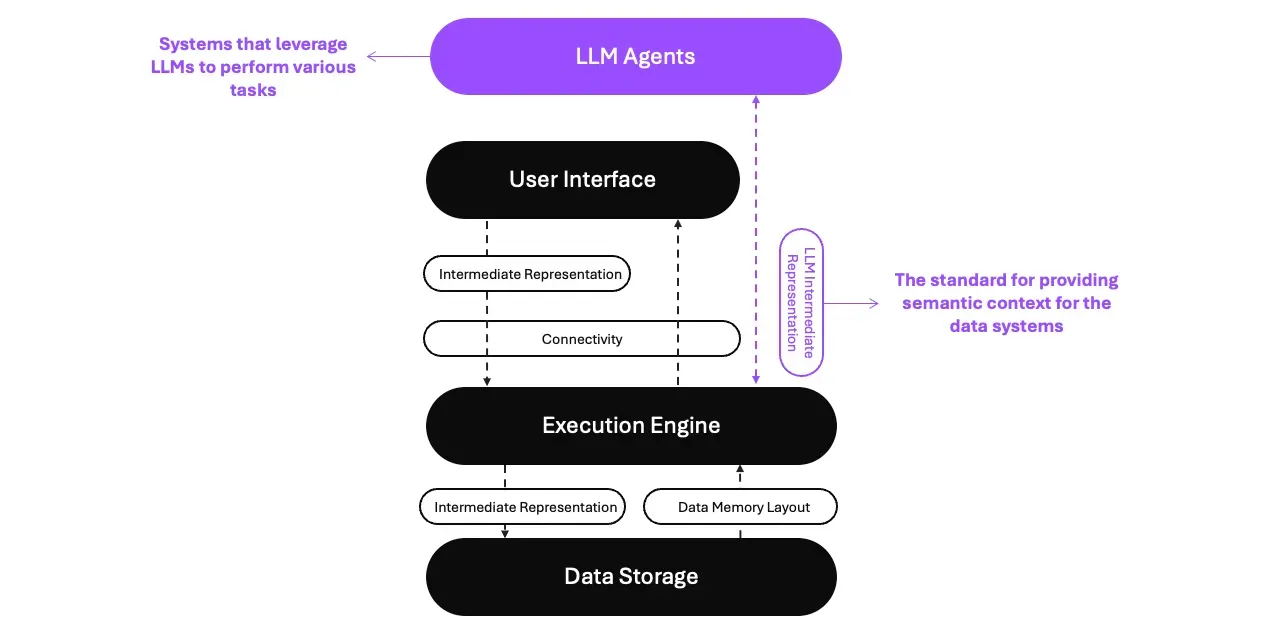
The component for LLM Agents (Purple highlighted in the diagram)
With these two additional designs on top of the existing composable data system, we can achieve two things.
- Context to LLMs: We can provide the necessary context to LLMs so that they can understand the meaning of the data structure in the business.
- Logical plan generation: The user interface, based on the execution engine, can generate different logical plans in the execution engine based on the queries sent from different user personas and contexts. This is done based on the predefined semantic relationships, calculations, aggregations, access control, and policies in the LIR.
The Semantic Engine
To better understand user queries and provide accurate results, it is essential to use LIR to provide context for the execution engine. The semantic engine should be designed to be embeddable into the LLM agent's architecture and designs.
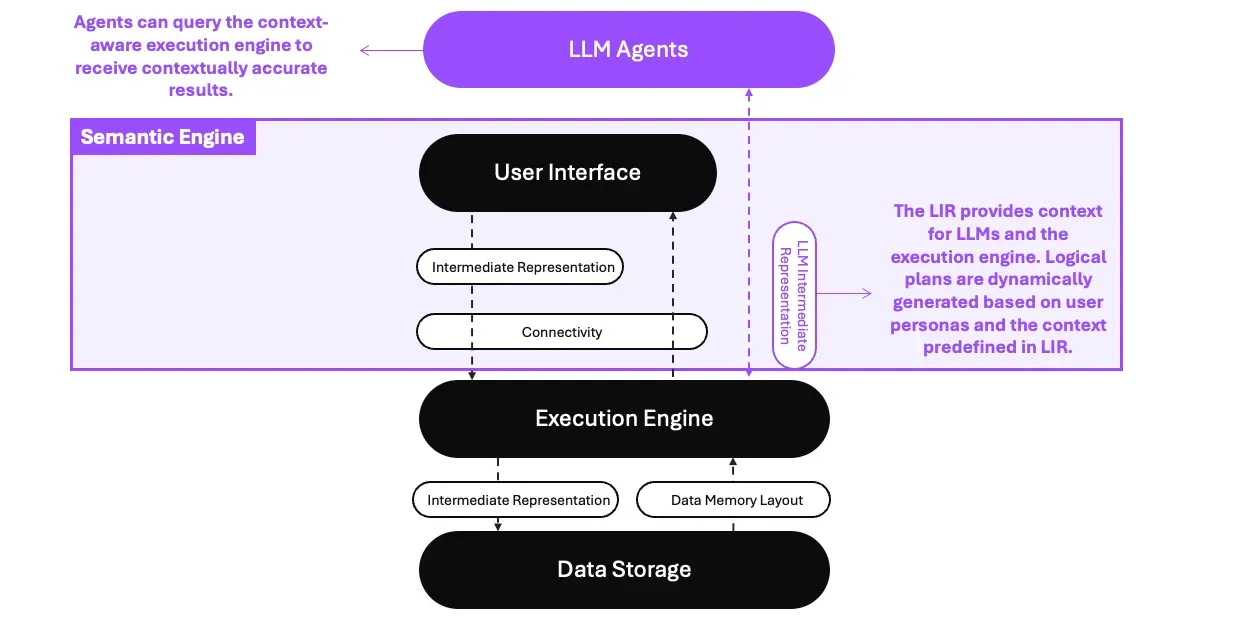
How the Semantic Engine works
This context includes the user's persona, such as their role, permissions, and preferences, and the semantic context of the data, including relationships and hierarchies.
By recognizing this information, the system can ensure that queries return contextually accurate results. This approach transforms the execution engine into a "Context-aware" execution engine or the "Semantic Engine."
Sounds awesome? Now, you might start thinking. That sounds great on paper, but what exactly does the implementation look like?
This is the reason why we started the project Wren AI.
Introducing the Wren AI project
The Wren AI is the LLM agent that is built on top of the semantic engine, Wren Engine; within the Wren Engine, we’ve designed the LIR called the “Modeling Definition Language(MDL).”
The implementation has shown that the MDL could help bring the context to LLMs through the RAG architecture and predefined a context-aware layer in the logical plan during the query planning phase; the SQL queries passed into Wren Engine will dynamically generate logical plans based on different user personas, and semantic context provided by the MDL.
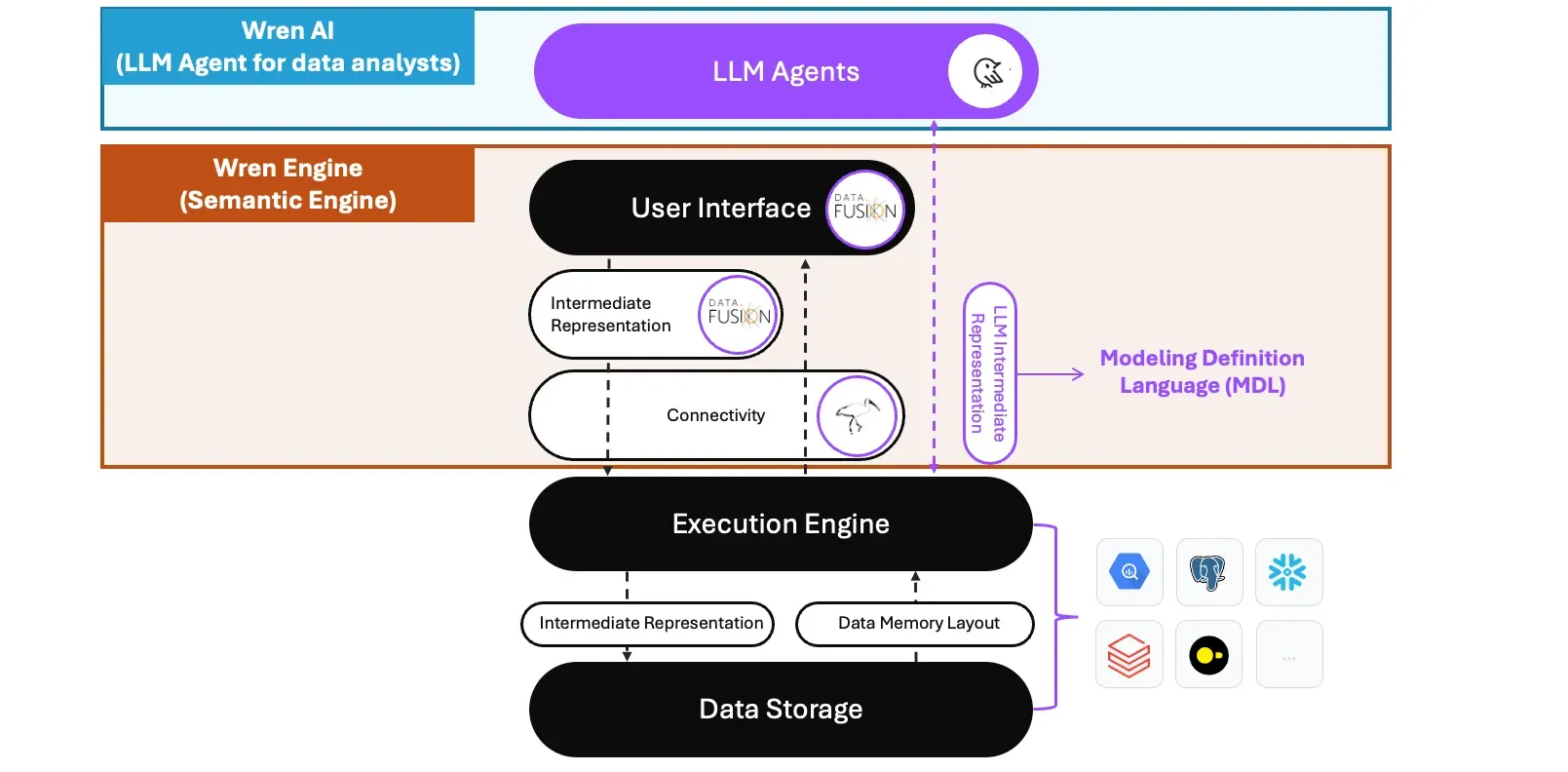
The Wren AI project in the composable data system
The Modeling Definition Language (MDL)
A Modeling Definition Language provides a formalized syntax and rules for describing data models, relationships, transformations, and analytics logic in a structured, code-like format.
It serves some important purposes below:
- Defining Business Terminology and Concepts: It allows for the precise definition of business terms, ensuring that when users query data using familiar terms like “revenue” or “customer satisfaction,” the system knows exactly what data to retrieve and how to process it.
- Mapping Data Relationships: By defining how different data entities relate to each other, the language facilitates complex analyses that can uncover insights into customer behavior, product performance, and market trends.
- Simplifying Calculations and Aggregations: It includes predefined rules for calculations and aggregations, making it easier for users to perform advanced data analysis without understanding the underlying mathematical operations.
- Access Control: MDL enables precise and flexible management of user permissions and data access policies directly within the data model, ensuring that data governance and security are seamlessly integrated into the analytics workflow.
Learn more about MDL in our documentation.
The Wren Engine
The Wren Engine is the semantic engine of the Wren AI project; the engine is based on DataFusion (Work in progress) as the query engine (internal IR and user interface) and uses Ibis as the unified API interface for data sources.
The Wren Engine will generate different logical plans based on the queries sent from different user personas and contexts according to predefined semantics in the MDL.
The Future of LLMs in the Data Systems with Wren AI
Open-source
The Wren AI project is fully open-sourced on GitHub, which every LLM developer or user can host freely as the AI agent for ad-hoc and analytics use cases, with any LLM, and the Wren Engine can be used as the semantic engine for internal and external AI agents' development.
Composable
The Wren engine aims to be compatible with composable data systems. It follows two important traits: Embeddable and interoperability. With these two designs in mind, you can reuse the semantic context across your AI agents through our APIs and connect freely with your on-premise and cloud data sources, which nicely fit into your existing data stack.
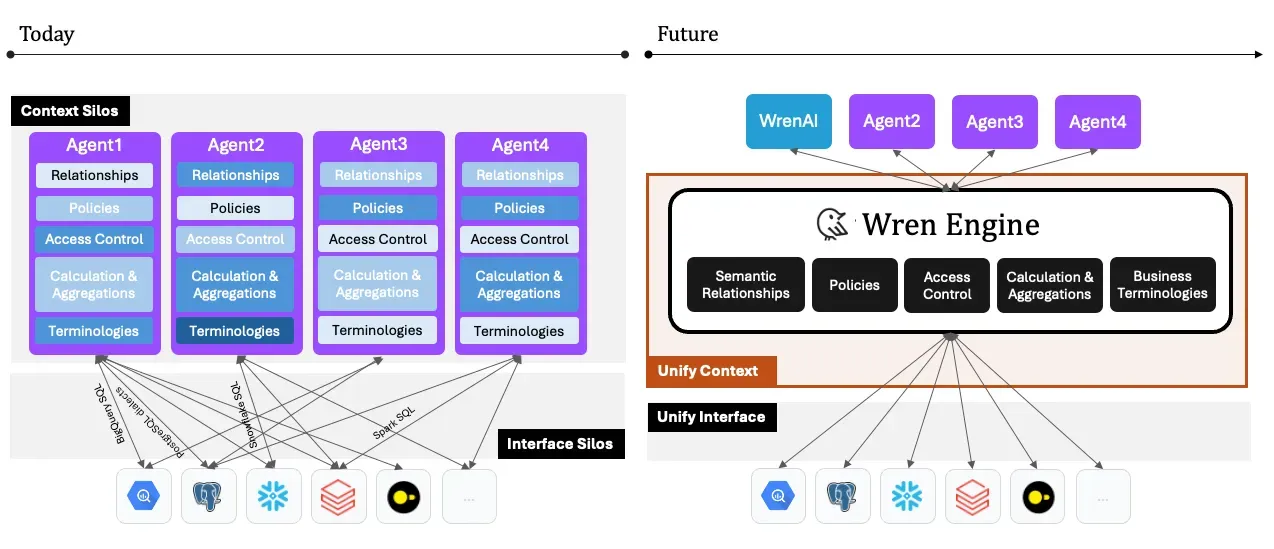
Today, without a semantic engine, every agent has to use different dialects to talk to every engine and has to deal with semantic mapping to data sources in silos.
You can check out more details on our GitHub.
Final remarks
Hope this post can start a new conversation in the composable data system and make data more accessible and democratized by AI(LLM).
If you have any thoughts that you would like to discuss on the topic, feel free to leave a comment in this post. Thanks!
Thank you Andrew Lamb, Cheng Wu, Colleen Huang, Jia-Xuan Liu, Jimmy Yeh, William Chang, who reviewed the post and provided feedback!
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free TrialRelated Posts
Fueling the Next Wave of AI Agents Building the Foundation for Future MCP Clients and Enterprise Data Access
How Wren Engine Powers the Semantic Layer for AI-Driven Workflows, Unlocking Context-Aware Intelligence Across the MCP Ecosystem
Apr 11, 2025Powering Semantic SQL for AI Agents with Apache DataFusion
Bridge the Gap Between AI and Enterprise Data with a High-Performance Semantic Layer and Unified SQL Interface for Model Context Protocol (MCP)
Aug 20, 2024How we design our semantic engine for LLMs? The backbone of the context layer for LLM architecture.
The advent of Trend AI agents has revolutionized the landscape of business intelligence and data management. In the near future, multiple…

Keep reading
 Product
ProductFueling the Next Wave of AI Agents Building the Foundation for Future MCP Clients and Enterprise Data Access
How Wren Engine Powers the Semantic Layer for AI-Driven Workflows, Unlocking Context-Aware Intelligence Across the MCP Ecosystem
 Insight
InsightPowering Semantic SQL for AI Agents with Apache DataFusion
Bridge the Gap Between AI and Enterprise Data with a High-Performance Semantic Layer and Unified SQL Interface for Model Context Protocol (MCP)
 Product
ProductHow we design our semantic engine for LLMs? The backbone of the context layer for LLM architecture.
The advent of Trend AI agents has revolutionized the landscape of business intelligence and data management. In the near future, multiple…