Powering Semantic SQL for AI Agents with Apache DataFusion
Bridge the Gap Between AI and Enterprise Data with a High-Performance Semantic Layer and Unified SQL Interface for Model Context Protocol (MCP)

Jax Liu
Updated: Dec 18, 2025
Published: Apr 11, 2025

As AI agents become increasingly capable of performing complex tasks, their ability to access and understand enterprise data remains a significant bottleneck. While tools like the Model Context Protocol (MCP) have made it easier for agents to interface with external systems, querying structured data like databases still poses a major challenge. That’s where Wren Engine, powered by Apache DataFusion, makes a real difference. By combining a context layer with the high-performance, Rust-based DataFusion query engine, Wren Engine not only enables AI agents to comprehend the logic and relationships behind your data, but also ensures that queries are executed quickly and reliably, no matter the underlying database.

Wren Engine is a powerful semantic engine built for the Model Context Protocol (MCP), enabling AI agents to interact with enterprise data through a next-generation context layer. By embedding directly into MCP clients, it provides deep business context, precise data access, and governance. Designed to be semantic-first, interoperable, and embeddable, Wren Engine transforms AI into context-aware systems that truly understand your data model and logic, unlocking scalable, trustworthy AI across the enterprise.
Wren Engine also serves as the powerful SQL backbone of Wren AI, an open-source, next-generation Business Intelligence (GenBI) AI Agent. Designed to empower data-driven teams, Wren AI enables users to seamlessly interact with their data through natural language. Whether generating complex Text-to-SQL queries, visualizing insights through charts, building spreadsheets, or creating detailed reports and dashboards, Wren Engine ensures every interaction is accurate, efficient, and production-ready. With Wren AI, business users and analysts can unlock the full value of their data, no SQL expertise required.
In this post, we’ll explore how Wren Engine bridges the gap between AI and data, making AI-powered data interaction more semantic, efficient, and production-ready. Make AI agents truly understand your data.
The Importance of a Semantic Layer for AI Agents
The Model Context Protocol (MCP) establishes a standardized interface for AI agents to interact with various tools, enabling them to answer questions using external knowledge or request more accurate responses. However, when it comes to database queries, if an AI agent cannot understand your data, how can it provide fast and accurate answers?
For better performance, most AI agents rely on cloud-based large language models (LLMs), where each round of question-and-answer interaction incurs significant costs. Reducing the number of round trips is essential for improving efficiency. Accuracy remains the key factor in delivering meaningful results. Research on text-to-SQL highlights that clean and semantic metadata and database schemas are critical for enhancing answer performance.
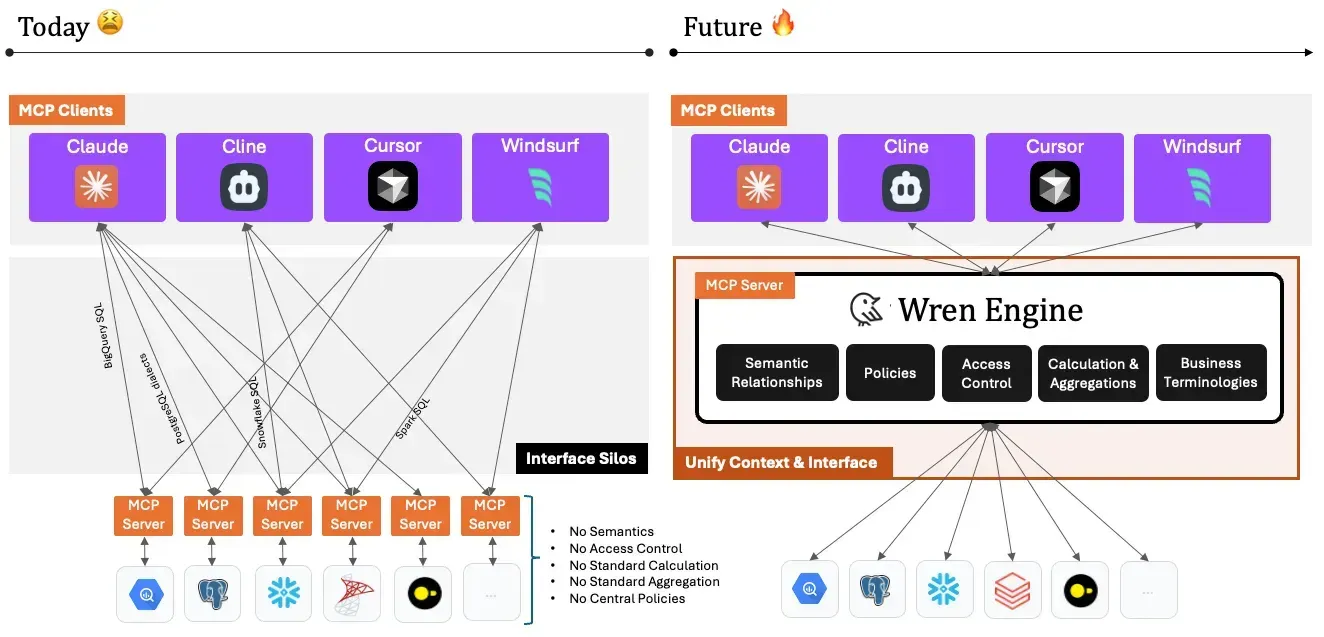
As a context layer, Wren Engine provides a structured approach to describing your data and offers a unified SQL interface for AI agents. This makes it easier for AI agents to comprehend your data and deliver accurate responses.
For more details on the importance of semantics, refer to Howard’s post: Fueling the Next Wave of AI Agents: Building the Foundation for Future MCP Clients and Enterprise Data Access.
In the next section, we’ll dive into the key requirements that AI agents need to effectively interact with structured data, and explore how Wren Engine is purposefully designed to meet those needs through a powerful context layer and unified SQL interface.
Motivation: Bridging the Gap: Essential Requirements for AI Agents
Wren Engine bridges the gap between AI and data through a context layer and a unified SQL interface. It simplifies data modeling and ensures compatibility across various SQL dialects, enabling AI to deliver accurate and efficient query results.
Semantic Layer
To enable AI to effectively understand your data, the most critical aspect is bridging the gap between AI and your data through a context layer. We have developed a unified data description method called the Modeling Definition Language (MDL), which uses a structured and human-readable JSON format. The primary concept of MDL is to describe your data at a logical layer. By defining your table as a Model, which acts as a virtual table containing only the columns you wish to expose, you can make your data more semantic without affecting the actual data. Additionally, you can define Relationships and describe the connections between models, which is essential for helping AI understand these relationships.
The Model serves as a logical layer that wraps the physical table. It can be used to control what AI can access or to apply pre-processing to the physical columns.
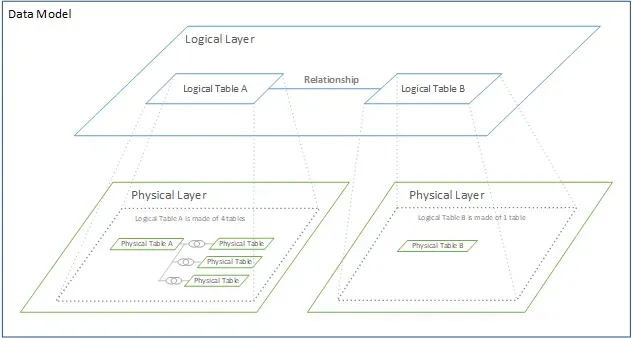
For example, Wren Engine dynamically rewrites the following SQL query:
Into another SQL query with a subquery:
The subquery is generated dynamically based on the MDL definition. For more details, refer to the Wren Engine Data Modeling documentation.
Unified SQL Interface
To facilitate communication with various databases, AI agents often encounter SQL syntax issues due to differences in dialects. Wren Engine provides a unified SQL interface, allowing AI agents to query multiple databases using a generic SQL syntax. Wren Engine then transpiles the SQL into the specific dialect required by the target database.
Additionally, using an AI agent to answer questions is typically an ad-hoc SQL scenario. Offering a low-latency SQL interface is highly beneficial in such cases. Delivering clear error messages and suggestions is also crucial, as AI often requires iterative feedback from the server to refine its queries and responses.
Architecture (version 1)
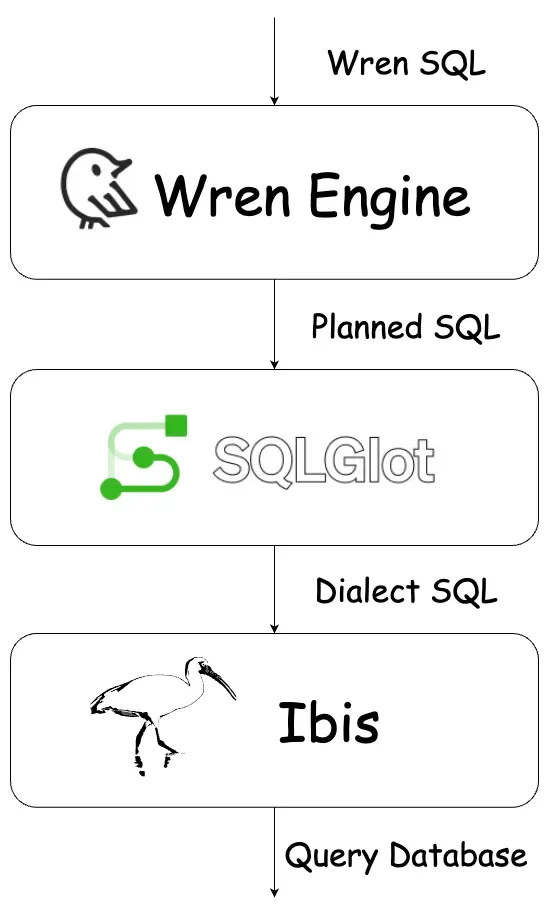
To implement the semantic engine, we began by forking Trino’s SQL layer to build the foundation of Wren Engine’s SQL layer. A key component is the SQL rewriter, implemented using Antlr4 Visitor, which takes the WrenMDL and input SQL to generate a SQL query enriched with necessary information, such as constructing subqueries for models and building expressions for columns. The planned SQL is then transpiled into a specific dialect and executed by the data source. Leveraging sqlglot, we enable seamless SQL dialect translation, while ibis-project provides a unified interface for querying various databases. For optimal performance, the generated SQL is fully pushed down to the data source, ensuring efficiency and scalability.
Challenges
SQL Dialect Compatibility
Implementing the SQL rewriter required handling the vast diversity of SQL syntax across databases. Applying rewrite rules for different use cases was time-consuming, and aligning the SQL base with the unique specifications of each database proved to be difficult. For example, legacy MySQL versions (before 8.0) do not support Common Table Expressions (CTEs), making it challenging to convert CTE-based queries into compatible forms. Similarly, the UNNEST syntax varies across dialects—while it can generally be used as a select item or table factor, BigQuery only supports it as a table factor.
Limitations of SQL-Layer Rewriting
Transforming one Abstract Syntax Tree (AST) into another purely at the SQL layer is inherently complex. A more robust and scalable solution would involve planning the query into an intermediate representation (IR) before rewriting, though this requires significant architectural investment.
Performance Bottlenecks in Legacy Architecture
The original implementation of the SQL rewriter relied on Trino’s SQL parser, which is built in Java. This introduced optimization and performance issues in production environments. Since the legacy codebase was not built with high-performance execution in mind, it struggled under real-world workloads, prompting the need for a more efficient and scalable solution.
Current Design: How Apache DataFusion Powers Wren Engine’s Innovation

Apache DataFusion is an extensible query engine written in Rust that uses Apache Arrow as its in-memory format. It provides libraries and binaries for developers building fast and feature-rich database and analytic systems, customized to specific workloads. The native performance of DataFusion is exceptional, allowing us to focus on implementing the functionality of data modeling.
Innovation 1: Data Modeling in the LogicalPlan Layer
As mentioned earlier, transforming SQL purely at the SQL layer presents numerous challenges. The LogicalPlan layer serves as an excellent intermediate representation (IR) for semantic rewriting. Planning a SQL query into a LogicalPlan acts as a form of SQL standardization, where different SQL constructs can be mapped to the same logical representation. For example, a CTE table and a subquery are equivalent in the LogicalPlan layer, both being represented as a Subquery plan. This significantly reduces the scope of SQL syntax we need to handle.
Another key advantage of DataFusion is its Unparser, which can convert a LogicalPlan back into SQL text. This feature aligns perfectly with Wren Engine’s goal of pushing down full SQL queries to remote databases. Additionally, DataFusion supports transforming the LogicalPlan into formats like protobuf or substrait, further enhancing its flexibility and usability.
Innovation 2: Strict Checking During SQL Planning
When planning a SQL query, DataFusion performs strict validations to ensure the query’s correctness. These validations include checking whether the table or column exists and verifying that the column type is valid for the specified functions or operators. This allows us to detect and verify invalid SQL queries before they are executed on the data source, reducing query latency and improving efficiency.
Additionally, the error messages provided by DataFusion’s logical planner are clearer and more standardized. The DataFusion community is actively working on improving error messages. For example, enhancements include appending node spans to errors (Attach Diagnostic to more errors) and suggesting candidate functions when the intended function is not found. These improvements are particularly beneficial for AI agents as they help correct queries and refine their behavior more effectively.
Innovation 3: Custom Rewrite Rules for LogicalPlan in Wren Engine
Apache DataFusion provides powerful tools like UserDefinedLogicalNode and AnalyzerRule to enable custom logical plan strategies. Wren Engine leverages these features to implement its modeling strategy effectively. For instance, the ModelPlanNode is used to represent Model in the logical plan, while ModelAnalyzeRule and ModelGenerationRule dynamically generate subquery SQLs tailored to specific models.
These custom rules also help bridge gaps between SQL dialects. Let’s look at some cases.
Case 1: The Gap of Timestamp with Timezone Literal
Handling timestamp literals with time zones is a common challenge due to differences in SQL dialects. While many databases support timestamp literals with time zone information, the syntax and behavior can vary significantly between systems. This inconsistency creates a gap that must be addressed when working with multiple databases.
For example, most databases support the following SQL syntax for timestamp literals with time zones:
However, ClickHouse does not support parsing a timestamp literal with a time zone directly. Instead, you need to use the DateTime([time zone]) type or specific parsing functions (e.g., parseDateTimeBestEffort), though even these cannot parse the literal directly:
Another example is Microsoft SQL Server (MSSQL), which uses the AT TIME ZONE keyword to assign a time zone to a timestamp literal:
Alternatively, MSSQL provides the DATETIMEOFFSET type, but it only accepts offsets, not time zone names:
These examples highlight the structural differences in SQL syntax across dialects. To address this gap, one approach is to parse the literal into its datetime and time zone components, then construct the required SQL for each specific dialect. However, a more general solution is to evaluate all timestamp literals to the UTC time zone before querying the database. This allows us to maintain a consistent structure, such as:
With this approach, we only need to handle type name differences for timestamps without time zones.
Case 2: The Gap of Type Coercion Behavior
Type coercion refers to the implicit type conversion that databases perform automatically under certain conditions. However, the rules for type coercion vary across databases. As a result, the same SQL query with the same table schema might be valid in some databases but invalid in others.
For example, consider the following SQL query:
This query is valid in Postgres and DuckDB but not in BigQuery. In BigQuery, it would return an error message like:
Additionally, in BigQuery, TIMESTAMP WITH TIME ZONE is referred to as TIMESTAMP. Therefore, the equivalent SQL for BigQuery would look like this:
According to BigQuery’s conversion rules, it does not support implicit conversion from DATE to TIMESTAMP. However, explicit conversion is supported:
While it is understandable why BigQuery does not allow implicit type coercion between DATE and TIMESTAMP WITH TIME ZONE, this limitation can be frustrating for users seeking a unified SQL experience.
DataFusion provides a default rule called Type Coercion to address this issue. Here’s an example using a Rust program to demonstrate how DataFusion handles this:
The output would look like this:
As shown, DataFusion automatically adds explicit casting for date_col. The generated SQL becomes valid for BigQuery after a simple function name mapping (e.g., replacing now with current_timestamp).
By leveraging DataFusion, we can easily apply various rules to logical plans, reducing the syntax gaps between different SQL dialects and providing a unified SQL interface for AI agents.
Easy Integration with Python
DataFusion, being a pure Rust project, offers seamless integration with Python through PyO3. This allows developers to build Python bindings effortlessly, enabling interoperability with powerful Python-based tools. For instance, Wren Engine leverages Python libraries like sqlglot and ibis-project, both of which are pure Python projects to connect with various data sources.
Additionally, by utilizing FastAPI, developers can create robust HTTP services, while the MCP Python SDK facilitates the construction of an MCP server tailored for AI agents. This integration ensures that Wren Engine can seamlessly bridge the gap between Rust’s performance and Python’s extensive ecosystem, making it a versatile choice for modern data systems.
A Thriving Community
The DataFusion community is highly active and continuously growing, with new contributors joining regularly and numerous commits being merged daily. This vibrant ecosystem ensures that the project remains well-maintained and evolves rapidly to meet emerging needs.
For Wren Engine, this active community provides a solid and reliable foundation, ensuring long-term sustainability and access to cutting-edge features. By building on DataFusion, Wren Engine benefits from a collaborative and innovative environment, making it a future-proof choice for modern data systems.
Conclusion
Wren Engine, powered by Apache DataFusion, bridges AI and data with a context layer and a unified SQL interface. By leveraging DataFusion’s LogicalPlan, it overcomes SQL dialect challenges, ensuring accuracy and efficiency. With strong community support and exceptional performance, Wren Engine is a future-proof solution for modern data systems.
Wren Engine is Fully Open Source!
Explore Wren Engine’s capabilities firsthand by visiting 🔗our GitHub repository, licensed under Apache 2.0.
Try it yourself by connecting your MCP clients to Wren Engine and witness the magic of semantic data access. The Wren Engine MCP server is still in its early phase, and we are actively improving it. We warmly invite you to join our community and help accelerate the future of MCP.
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free TrialRelated Posts
Powering AI-driven workflows with Wren Engine and Zapier via the Model Context Protocol (MCP)
Use semantic understanding, SQL generation, and email automation to streamline data requests with LLM agents and Wren’s powerful query engine.
Aug 20, 2025Game On: How Wren AI Transforms Backend Gaming Data Into Actionable Insights
How Wren AI Turns Natural-Language Questions Into Cost-Efficient SQL to Accelerate Insights from Gaming Data

Keep reading
 Product
ProductPowering AI-driven workflows with Wren Engine and Zapier via the Model Context Protocol (MCP)
Use semantic understanding, SQL generation, and email automation to streamline data requests with LLM agents and Wren’s powerful query engine.
 Insight
InsightGame On: How Wren AI Transforms Backend Gaming Data Into Actionable Insights
How Wren AI Turns Natural-Language Questions Into Cost-Efficient SQL to Accelerate Insights from Gaming Data