How Snowflake Is Building the Most Powerful SQL LLM in the World
Last month, Vivek Raghunathan, VP of Engineering at Snowflake, discussed the pioneering Snowflake Copilot, here's what we learned.

Howard Chi
Updated: Dec 18, 2025
Published: Aug 20, 2024

Note: this post predates Agentic GenBI. The analysis below still holds, but it frames Wren AI as a text-to-SQL tool. Today Wren AI is an agent that reasons over a governed context layer, with skills and memory, for humans and agents alike. Read "Introducing Agentic GenBI" to see how the product works now.
AI has created a new opportunity for data democratization. By harnessing the power of language model comprehension to generate insights without requiring SQL, a significantly larger number of users will be able to uncover valuable insights that are currently buried in massive amounts of data.
Last month, Vivek Raghunathan, VP of Engineering at Snowflake, discussed the pioneering Snowflake Copilot at the Fully Connected conference. The video became publicly available on YouTube last week. The Wren AI team has been working on text-to-SQL for several months, and we learned a lot of thoughts and techniques Vivek shared in his latest talk about the SQL LLM topic. Today, I would like to arrange thoughts and learnings from this video. I hope this helps other developers like us accelerate text-to-SQL innovation faster together!
Wren AI’s mission is to democratize data by bringing text-to-SQL ability to any data source and industry. We believe in bringing the ability to make data accessible to any person.
If you are interested in the full video, check the link below! Snowflake Copilot
Now, let’s start!
AI today and the future in data analytics
Vivek talked about the current and future of AI in data analytics.
Today: AI that helps you
- Conversational copilot for analysts
- Natural language to SQL: Analyst-in-loop executes SQL
- Interface allows for iterative data and schema discovery
But the future will evolve into a fully-fledged conversational pilot for business users; this will empower individuals who don’t know SQL to simply ask questions in natural language and receive answers.
Future: AI you depend on
- Conversational pilot for business users
- Natural language to answers: No SQL expertise needed
- Interface that allows for interactive data and visualization
The goal is to create an interface that supports interactive data exploration and visualization, ultimately becoming an AI that users can rely on to accomplish their tasks efficiently.
Our thoughts:
This is also what we experienced in developing Wren AI. We believe there is still a limitation of current technology innovation to reach a full-fledged AI pilot for all business users; it’s like what we experience in self-driving cars. Over the years, car vendors have been rolling out autopilots to copilot with drivers. Until it is proven that a high degree of accuracy and safety with the use cases of copilots is possible, we will still need data analysts to assist with AI.
Is Text-to-SQL that simple in the real world?
Vivek mentioned that text-to-SQL is like an iceberg problem, issues appear simple on the surface but are immensely complex underneath.
Quote from the talk:
“I’ve seen countless Twitter demos about this, I just saw one recently. Why not use standard approaches and buzzwords like schema recognition? Why not fine-tune on a schema? There’s a new leader on the Spider leaderboard every so often, so why waste time on this trivial problem?” I’m here to tell you it’s not that simple
A few obvious challenges you will quickly face, which are mentioned in his talk:
- The real world has messy schemas and data, often with databases containing tens of thousands of tables and hundreds of thousands of columns
- Real-world semantics are even messier: you might have a table with columns labeled rev1, rev2, and rev3, but which is the revenue column? Is it in US dollars or local currency? Was it deprecated in an email sent weeks ago? Which one is the current source of truth?
- It gets more complicated across tables, with multiple ways to join them correctly.
Our thoughts
Indeed, it’s not simple at all!
Wren AI is very focused on solving the challenge between data and semantics; we believe the key to making text-to-SQL reliable, at its very core, is how to build a reliable semantic engine that responds to the semantic architecture on top of existing data structure, such as defining semantic relationships, calculations, aggregations, LLMs should learn how to deal with different context in different scenarios, it highly depends on a robust context layer.
Snowflake Experiments from v0 to v4
Snowflake has been through several experiments from v0 to v4; thankfully Vivek generously shared what they tried, learned, and iterated in the following version to make improvements of text-to-SQL innovation.
Let’s dive in!
V0: Optimized for Spider
In the talk, Vivek mentioned:
To tackle this, we began with a data set called Spider from Yale, optimizing our model for this benchmark. Our initial model performed well, but when tested on an internal data set reflective of real-world use, its accuracy plummeted.
This highlighted the need for a robust semantic catalog retrieval system
The first iceberg (Challenge) they faced:
In the V0 version, they see using the Spider dataset to achieve the best model at 82%, Zero-shot GPT-4 (no-optimization) at 74%, but in real-world data, the accuracy plummeted to 9% using their best model, and using GPT-4 with prompt-optimized get 14%.
That is when they start realized the important of “Semantic Catalog” which semantic plays a huge part in data retrieval, since pre-trained LLMs knows nothing about your business context, the only way is to provide semantics through RAG.
Our thoughts:
Semantics is key for solving text-to-SQL challenge, and it’s the centric core design when we started implementing Wren AI.
V1: Retrieval is key in the real world
In the follow up V1 version, the Snowflake team start by thinking… If we can bring web-quality search to enterprise metadata search and feed the output into an LLM, performance can potentially get radically better.
In other words, to solve a simpler problem, what should we pack into the context of this LLM, we’re going to solve a harder problem first:
How can we adapt a consumer-grade web search engine to the problem of conversational catalog search?
Below is the result, the best model of Snowflake improves from 9% to 24%, and GPT-4 version also jumps from 14% to become 28%. Thus, the intuition that semantic catalog retrieval is essantial holds true.
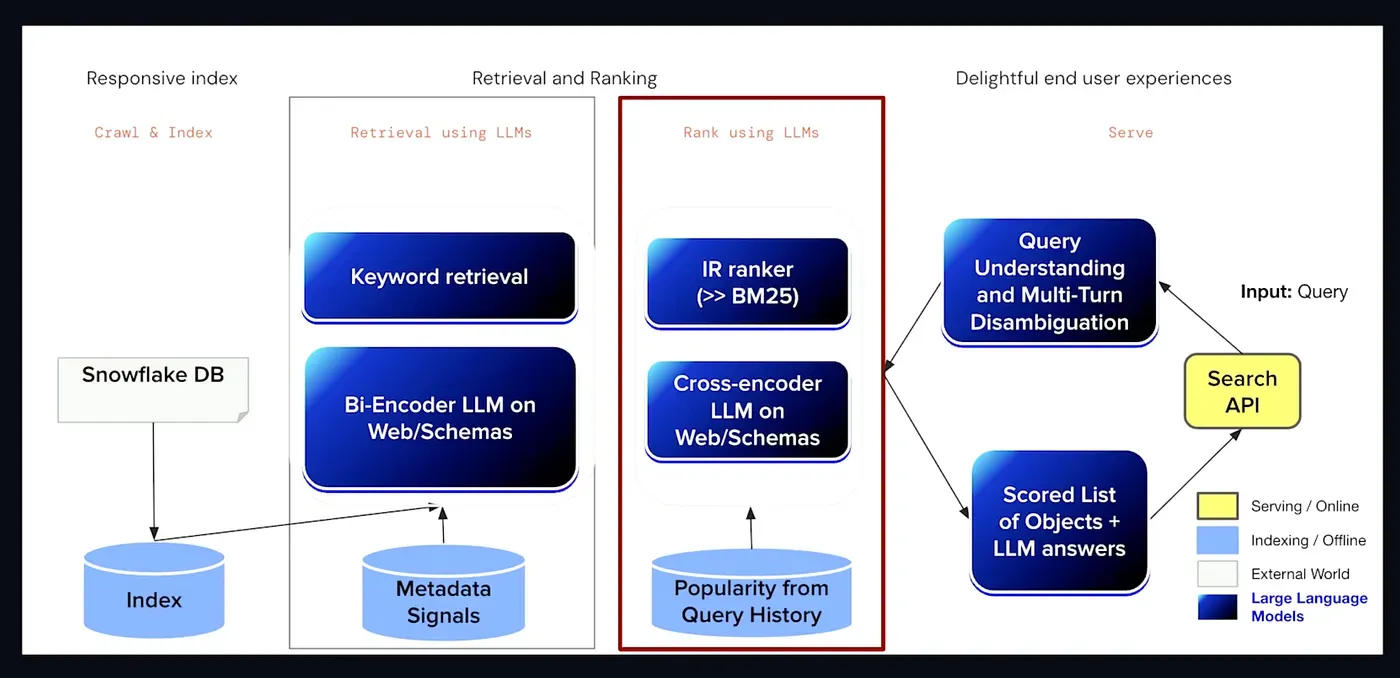
Architecture diagram of how conversational catalog works
Vivek mentioned how they retrieve the conversational catalog retrieval at Snowflake
At Snowflake, user queries come in and go through a query understanding layer, which includes multi-turn disambiguation and query rewriting. Every known trick from the IR and NLP literature is employed.
In the middle, we’re adapting a consumer-grade search engine, Neeva, to the problem of conversational catalog retrieval. This involves both sparse and dense retrieval and ranking techniques, such as keyword retrieval, bi-encoder LLM for retrieval, IR ranker (which outperforms BM25), and a cross-encoder LLM for ranking.
Of course, all the usual secret sauce is included. We train these models on web and schema data, incorporating factors like popularity, authority, and freshness. After extensive work, we ended up with a system that meets our standards.
The second iceberg (Challenge) they faced:
The Snowflake team is also facing another challenge: the rater. They Re-annotated everything by hand, added more complex examples to evaluate the performance, and sliced based on data semantics such as single table vs. multi-table and simple join vs. complex join.
Below is what Vivek shared in his talk:
That was more reflective of real-world use, but it had subtle errors. So, what is the crux of the issue here? For those of you who write SQL, it isn’t easy. It’s not just learning the syntax; it’s learning the underlying semantics of the data and thinking like an analyst.
Our annotators were not highly paid analysts, and even an analyst takes an hour to understand a database before writing queries. They have a very structured process for learning how data is organized. There are multiple other complex issues, such as join paths between tables that can cause problems, and phenomena like chasm traps and fan traps.
In other words, we’ve hit the iceberg, which means we must curate the data correctly. With the problem thus identified, the solution is simple: we manually curated everything. We did multiple rounds of validation and cross-checking. The cross-checking process is actually harder than it seems because it requires truly solving the problem to ensure accuracy.
Our thoughts:
This insight is quite interesting to us; while we haven’t done much retrieval optimization when implementing Wren AI. Currently, we only use Top-N selection from vector store; we are looking into further details of retrieval techniques to improve this area.
Our team is also building internal eval datasets that could have more complex scenarios with single and multi-table, as well as simple and complex join datasets, making sure the solution remains accurate in the real world.
Welcome to open new issues for discussion on this topic! Our team is willing to look into more improvements!
V2: Text2SQL Modeling Insights
Next, Vivek shared that despite these advances, the model still faced challenges in conversational capabilities. Optimizing for SQL tasks had crippled its ability to handle conversations and follow instructions.
Below are some insights they shared:
- Better base LLMs: It turns out code LLMs perform very well on SQL tasks.
- Better signals: Some come from LLM generation, such as comments, and some from classic techniques, like Snowflake documentation. One of his favorites is query history, which is a treasure trove of what people actually do.
- Chain of Thoughts: First, you pick the tables, then the joins, then the columns, then aggregate and finally check correctness at decode time. When LLMs produce JSON, there’s a dependency parser that checks the output against the schema.
With this new clean eval, they are seeing significant improvements, their base model 27% has become 39%, using GPT-4 jumped from 40% has become 46%.
The third iceberg (Challenge) they faced:
The next challenge they face in trying to build is a conversational co-pilot instead of a zero-shot Text-to-SQL solution. It needs to handle conversations and allow analysts to refine their queries as they go along.
Optimizing one part of the system will unintentionally deoptimize the whole thing. Two big issues arose:
- Model stopped being great at the instruction following because it only saw text-to-SQL tasks
- It became poor at conversation because it never encountered multi-turn cases, only zero-shot cases.
Our thoughts
The talk mentioned text-to-SQL challenge requires an interactive approach instead of a zero-shot approach. We at Wren AI are also pursuing this approach, we are still working on several experiences to improve.
Through our implementation, we implemented sophisticated processes in the “Augmentation & Generation” RAG pipeline, such as validation, correction, and clarification dialogs, to make sure LLMs fully understand the user’s intent. But of course, still a lot of areas to improve.
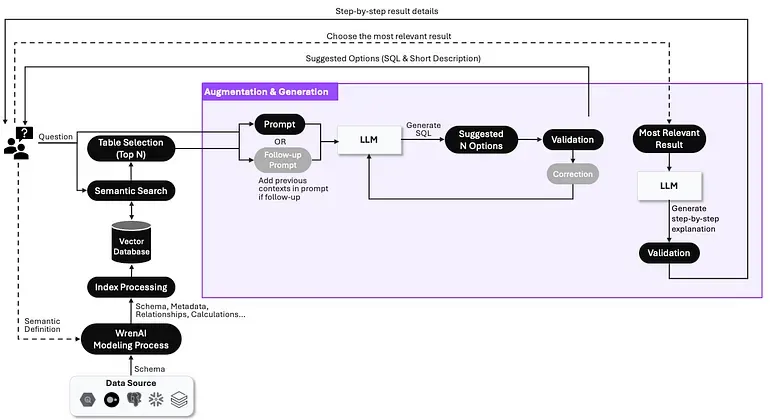
Augmentation & Generation phase in Wren AI
V3: Instruction-following, tool use
Vivek shared they retrained the LLM to follow instructions by giving it a mix of text-to-SQL tasks and more general-purpose instruction-following tasks. and they layered it in a Multi-LLM setup with an orchestrator LLM.
The orchestrator model’s responsibility is to have a conversation with the customer; it’s like an agentic approach. Allowing it to use another equally big text-to-SQL model whenever it needed to write SQL. This approach of smartly delegating tasks solved many problems.
And the numbers go even better, their best model used to be 38% now hit 41% due to the added instruction-following capability, and with GPT-4 plus optimization the eval reached 46%.
The fourth iceberg (Challenge) they faced:
Going from 46.4% to 99%, the goal of text-to-SQL is to, build a conversational co-pilot for business users who don’t know SQL. This is the opportunity, and they need 99% accuracy.
The goal is to build a conversational co-pilot for business users who don’t know SQL. This is the opportunity, and they need 99% accuracy.
Our thoughts
At Wren AI, we are also optimistic about the future of text-to-SQL. We believe that as LLM innovation accelerates, we will soon pair LLMs with semantic context to achieve near-human comprehension and true data democratization.
V4: Increasing accuracy to 99%
It’s now a work in progress at Snowflake! Using the semantic context provided by the customer to understand metrics, and join paths, etc.
Our thoughts
Looking forward to more sharing from Snowflake! Very exciting!
Final takeaways for all the lessons
Finally, Vivek shared his key takeaways and learnings from going through all the challenges, arranged below.
- 👏 The product is the entire e2e system: Not just LLM modeling
- 👏 Semantic catalog retrieval is critical: Power it by real LLM search engine
- 👏 Annotation quality for SQL is paramount: Annotators need to be experts
- 👏 Conversational SQL is an LLM grail problem: Complex instruction tuning, chain of thought, tool use
- 👏 Going 99% needs a breakthrough
That’s about it! Thank you Vivek and Snowflake team shared lot’s of valuable lessons in this talk, we’ve learned a lot from you!
Onward!
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free TrialRelated Posts
Beyond Dashboards How Conversational AI is Revolutionizing Structured Finance Analytics
How Wren AI transforms complex financial data into instant, actionable insights through natural language, no technical expertise required
Mar 31, 2025Fueling the Next Wave of AI Agents Building the Foundation for Future MCP Clients and Enterprise Data Access
How Wren Engine Powers the Semantic Layer for AI-Driven Workflows, Unlocking Context-Aware Intelligence Across the MCP Ecosystem
Apr 01, 2025Beyond Text-to-SQL: Why Feedback Loops and Memory Layers Are the Future of GenBI
How Wren AI’s Innovative Approach to Question-SQL Pairs and Contextual Instructions Delivers 10x More Accurate Generative Business Intelligence

Keep reading
 Insight
InsightBeyond Dashboards How Conversational AI is Revolutionizing Structured Finance Analytics
How Wren AI transforms complex financial data into instant, actionable insights through natural language, no technical expertise required
 Product
ProductFueling the Next Wave of AI Agents Building the Foundation for Future MCP Clients and Enterprise Data Access
How Wren Engine Powers the Semantic Layer for AI-Driven Workflows, Unlocking Context-Aware Intelligence Across the MCP Ecosystem
 Insight
InsightBeyond Text-to-SQL: Why Feedback Loops and Memory Layers Are the Future of GenBI
How Wren AI’s Innovative Approach to Question-SQL Pairs and Contextual Instructions Delivers 10x More Accurate Generative Business Intelligence